
목차(클릭하세요)

Gemma 4를 활용한 이유: 멀티모달 가능, 상업적인 사용도 가능
강의1: 내 컴퓨터에 나만의 AI 에이전트 육성하기 (1강)
강의2: 내 컴퓨터에 나만의 AI 에이전트 육성하기 (2강)
Ollama 공식 사이트: https://ollama.com
Gemma 4 모델 허브: https://ollama.com/library/gemma4
[강의 참고자료]
- 강의1: https://www.youtube.com/watch?v=eyFk27mwFJo&t=7s
- 강의2: https://www.youtube.com/watch?v=ZtVTeLQDyHQ
1. 로컬 AI가 필요한 이유
1-1. 클라우드 AI의 구조적 한계
클라우드 AI(ChatGPT, Gemini, Claude 등)를 사용할 때 실제로 어떤 일이 일어나는지 생각해보면 대략적으로 다음과 같음
내가 타이핑 한 명령어가 → 미국 서버로 날아가고 → 거기서 생성된 결과가 → 다시 내 화면으로 돌아옴
이 과정에서 3가지 문제가 생김•
비용: 입력할 때, 출력할 때 모두 토큰이 소비됨. 구독료 + API 비용 합치면 월 수십~수백만 원도 순식간에 나감
•
보안: 내 문서, 사진, 업무 데이터가 외부 서버로 전송됨. 금융권, 병원, 학교 같은 민감 데이터 환경에서는 사실상 사용 불가
•
인터넷 의존: 네트워크 없이는 아무것도 못 함. 비행기 안, 오프라인 현장에서 무용지물
1-2. 로컬 LLM AI가 해결하는 것들
문제 | 클라우드 AI | 로컬 AI |
비용 | 토큰 소진, 구독료 | 완전 무료 |
보안 | 외부 서버 전송 | 내 컴퓨터 안에서만 동작 |
인터넷 | 필수 | 불필요 |
상업적 활용 | API 비용 발생 | 라이선스에 따라 무료 가능 |
2. 오픈소스 LLM과 Ollama
2-1. 오픈소스 LLM이란?
•
LLM(Large Language Model): 대규모 텍스트 데이터로 학습된 언어 모델. ChatGPT, Claude, Gemini가 모두 LLM의 한종류임
•
오픈소스 LLM은 모델의 가중치(학습된 파라미터)를 공개해서 누구나 다운로드해 자기 컴퓨터에서 직접 실행할 수 있게 한 것.
클라우드 AI vs 오픈소스 LLM 핵심 차이:
•
클라우드 AI: 빅테크 서버의 슈퍼컴퓨터가 연산 → 내 화면에 결과 전송
•
오픈소스 LLM: 모델을 내 컴퓨터에 설치 → 내 CPU/GPU가 직접 연산
◦
기본적으로 나의 로컬컴퓨터에서 ‘추론’이 진행됨
2-2. Ollama란?
Ollama는 오픈소스 LLM을 내 컴퓨터에서 쉽게 실행할 수 있게 해주는 플랫폼.
마치 스마트폰 앱스토어처럼, 다양한 AI 모델을 검색하고 터미널 명령어 한 줄로 설치·실행할 수 있음
•
공식 사이트: https://ollama.com

•
Gemma, Llama, Mistral, Phi 등 수십 개의 오픈소스 모델 지원
•
macOS / Windows / Linux 모두 지원
2-3. Gemma 4란?
•
Google DeepMind가 공개한 오픈소스 멀티모달 LLM.
1.
Gemma 3와의 차이:
- Gemma 3: 텍스트 대화만 가능
- Gemma 4: 이미지 입력(멀티모달) 지원 → 사진 분석, OCR, 다국어 이미지 번역 가능
2.
핵심 특징:
- 완전 무료 (API 비용 없음)
어떤 모델들은 설치는 무료이지만 API비용이 발생하기도 함
- 상업적 사용 가능 라이선스 → 서비스 개발 후 판매 가능
2-4. 내 PC 사양별 모델 선택 기준
모델 이름의 숫자(E2B, E4B 등)는 파라미터 수를 의미함. 숫자가 클수록 더 똑똑하지만, 더 높은 사양의 컴퓨터가 필요함.

모델 | 권장 사양 | 특징 | 권장 메모리 | 최소메모 |
E2B | 구형 PC, 일반 노트북 | 가볍고 빠름, 기본 테스트용 | 8GB | 4GB |
E4B | 3년 이내 구입 PC / 맥북 | 균형 잡힌 성능, 실사용 추천 | 16GB | 8GB |
26B (기본값) | 고사양 PC / Apple Silicon | MoE 구조, 태그 없이 실행 시 자동 선택 | 24GB+ | 16GB |
31B | 워크스테이션 / RTX 4090 | 최고 품질, 상업 서비스 수준 | 32GB+ | 20GB |
처음 시작할 때는 e2b 로 시작하고 성능이 되야 e4b사용 가능 + 실제 서비스 배포 단계에서 더 큰 모델로 업그레이드하는 것을 권장함
3. Gemma 4 실행하기
3-1. Ollama 설치
1.
https://ollama.com 접속
2.
우측 상단 Download 클릭
3.
내 OS 선택 (Windows / macOS)
4.
설치 파일 실행 → 완료 시 시스템 트레이에 낙타 아이콘 생성
예전버전을 설치하고 싶다면? https://github.com/ollama/ollama/releases/tag/v0.23.2

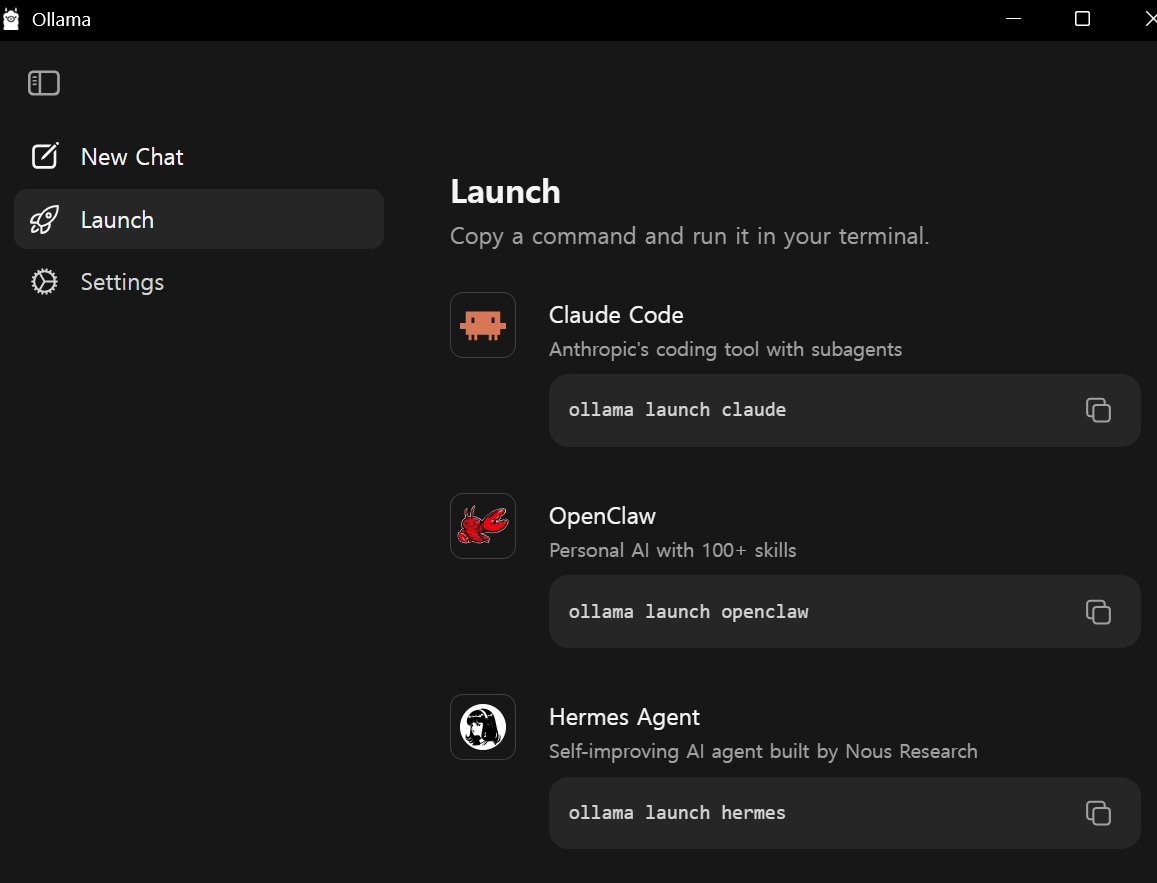
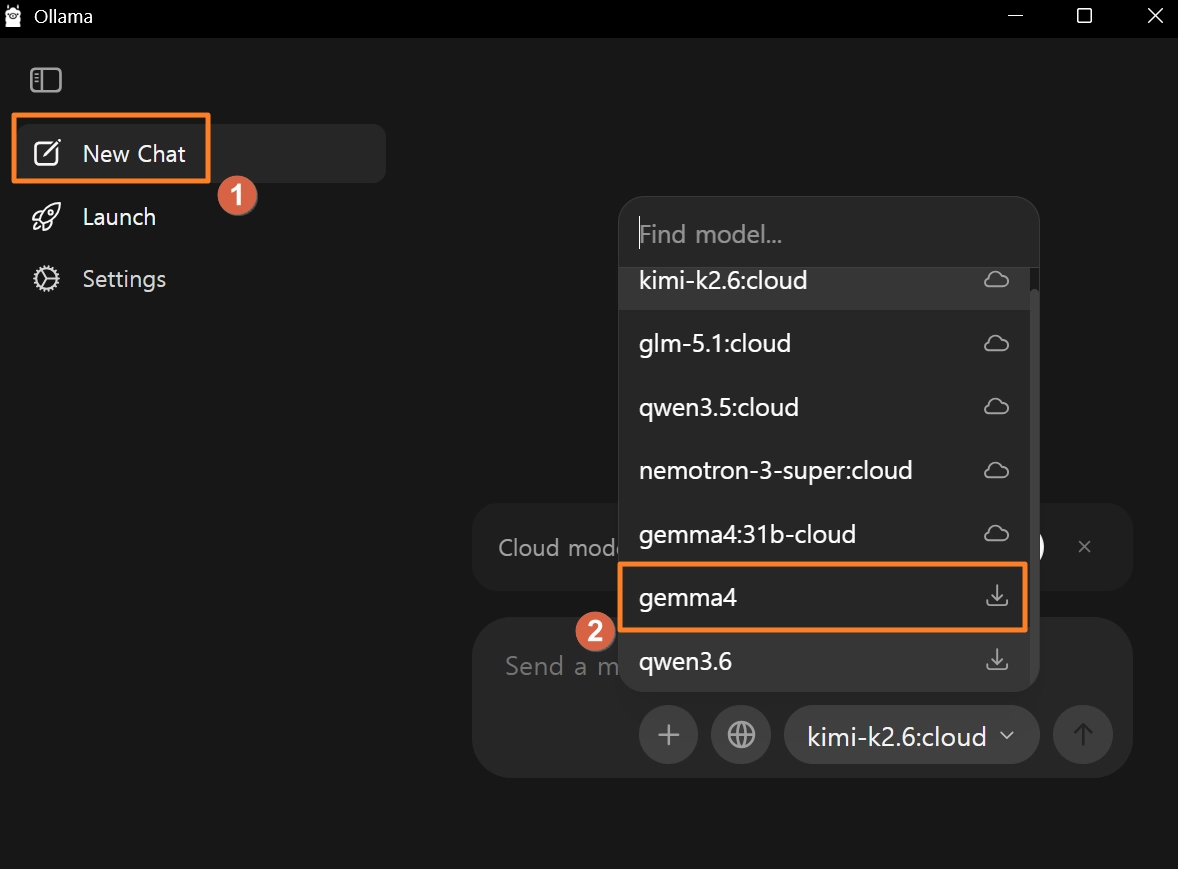
•
New Chat을 누른 뒤, 사용할 로컬 LLM모델을 선택할 수 있음
•
그림처럼 다운로드 아이콘이 보이면 직접 다운로드 받아야 한다는 것을 의미함.
[주의점]
1.
이미지에서 gemma4 옆에 구름 아이콘 없이 다운로드 아이콘(↓)이 붙어 있는 건 로컬 설치 가능한 모델이라는 뜻이고, gemma4:31b-cloud 처럼 구름 아이콘이 붙은 건 클라우드 연결 모델이라 토큰 소비됨. 주의 필요
2.
여기서 직접 다운로드하는 것을 권장하지 않음
터미널 설치를 권장하는 이유: gemma4:e2b 처럼 내 사양에 맞는 버전을 정확하게 지정할 수 있어서, 처음 설치할 때는 터미널 방식을 권장[셋팅하기]
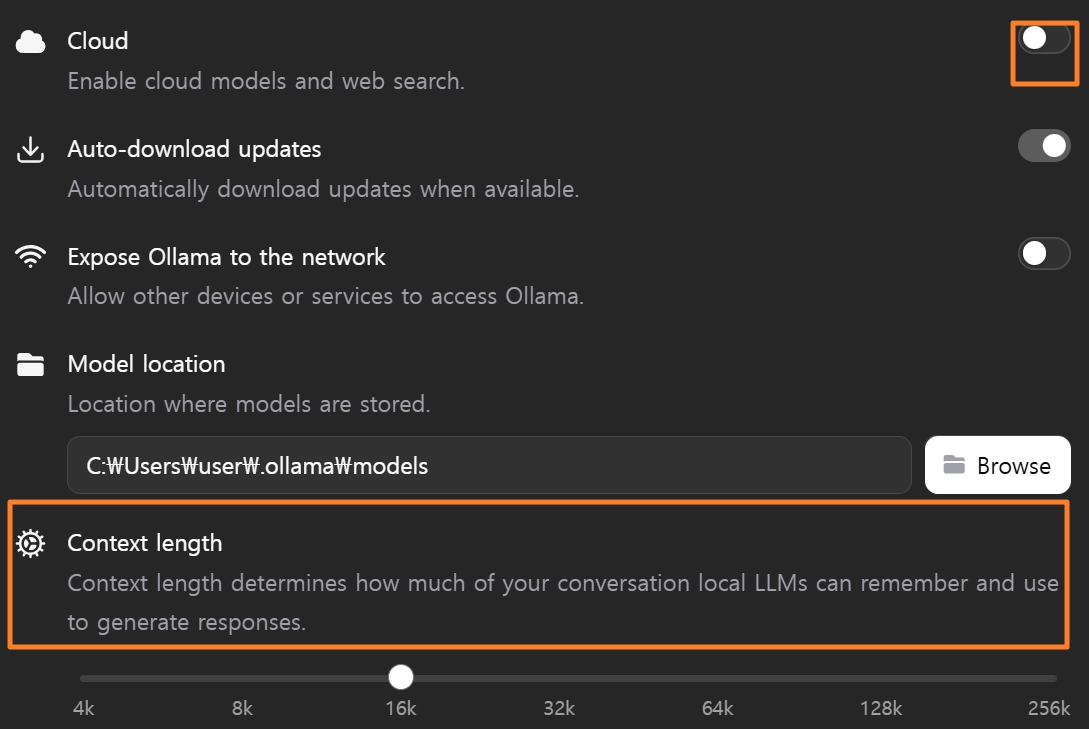
•
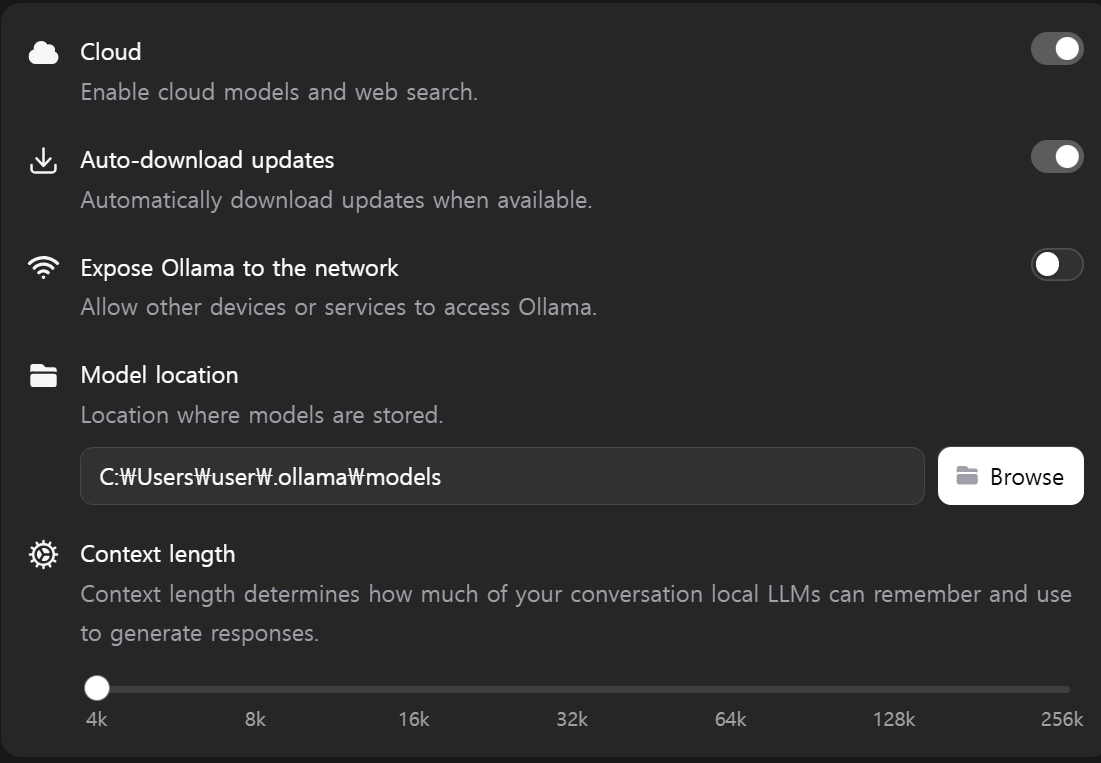
Cloud: 클라우드 모델 + 웹 검색 활성화 옵션
로컬 AI 목적이라면 OFF 권장•
Expose Ollama to the network : 다른 기기나 서비스에서 내 Ollama에 접근 허용
보안상 OFF가 기본값이 맞음•
Context length: 현재 4k
대화에서 AI가 한 번에 기억할 수 있는 텍스트 길이, •
4k는 상당히 짧음. 긴 문서 분석이나 코딩 작업 시 앞 내용을 잊어버림
•
최소 8k~16k 권장,
•
단, 값이 클수록 RAM 사용량 증가
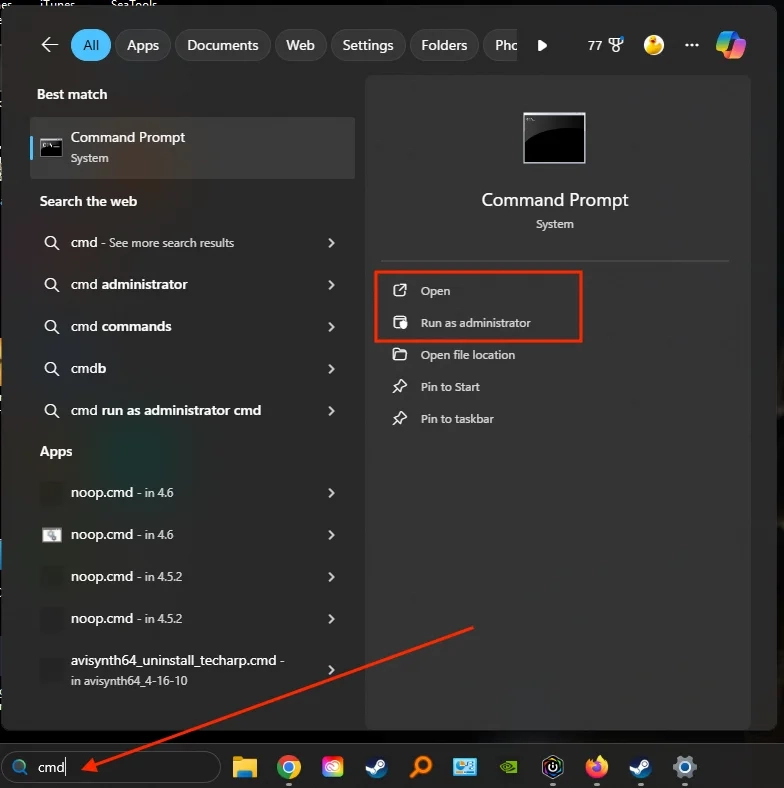
3-2. 터미널 열기
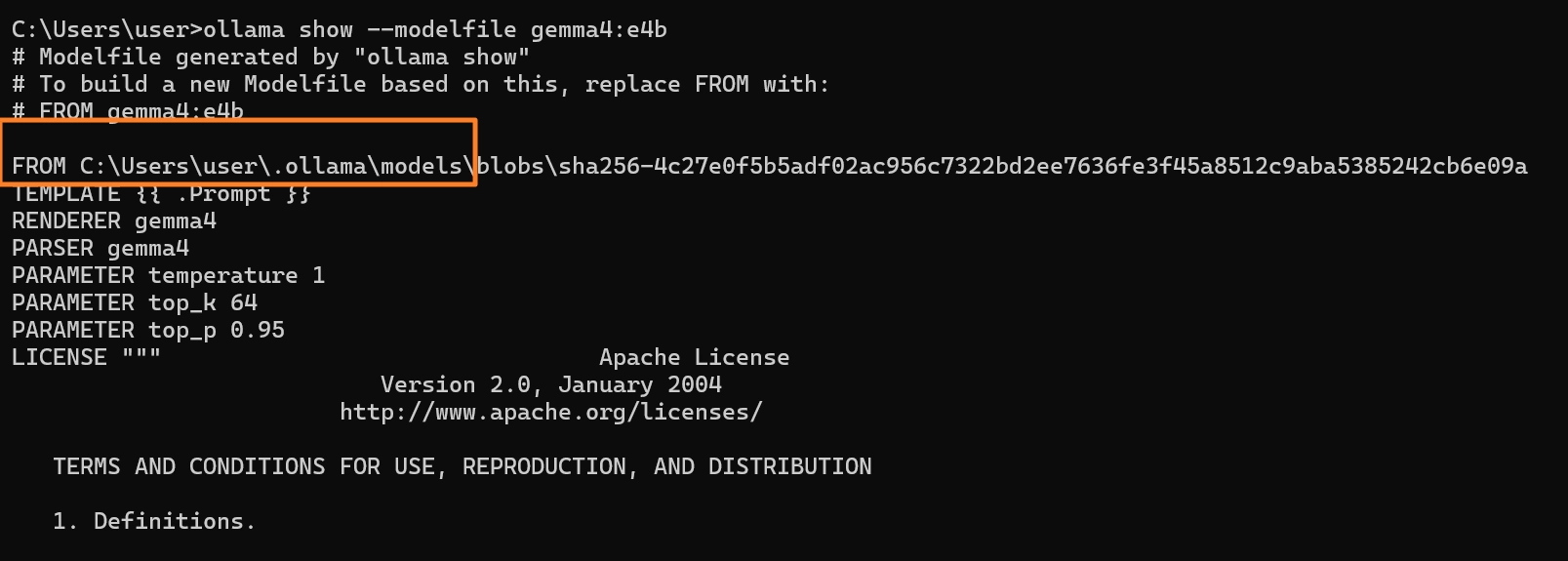
•
ollama가 설치된 경로는 다음 명령어로 확인가능
ollama show --modelfile gemma4:e4b
Bash
복사
macOS:
Spotlight(⌘+Space) → "터미널" 검색 → 실행
Plain Text
복사
Windows:
Win키 → 검색창에 "cmd" 입력 → 명령 프롬프트 실행
Plain Text
복사
3-3. Gemma 4 다운로드 & 실행
•
다운로드가 완료되고 나면, 터미널에서 바로 CLI기반으로 대화를 할 수 있음
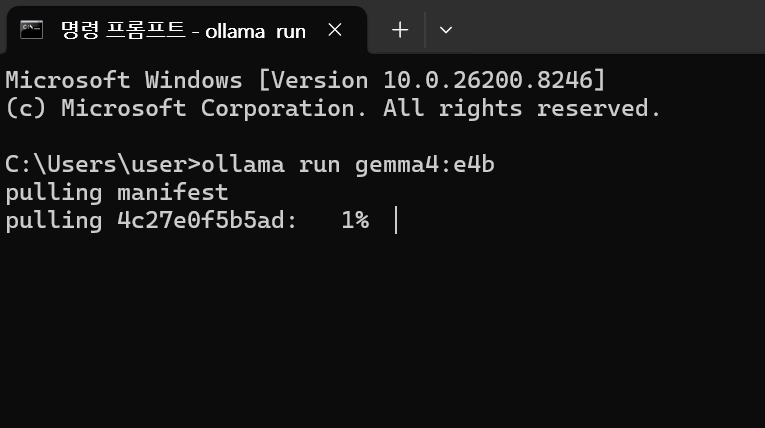
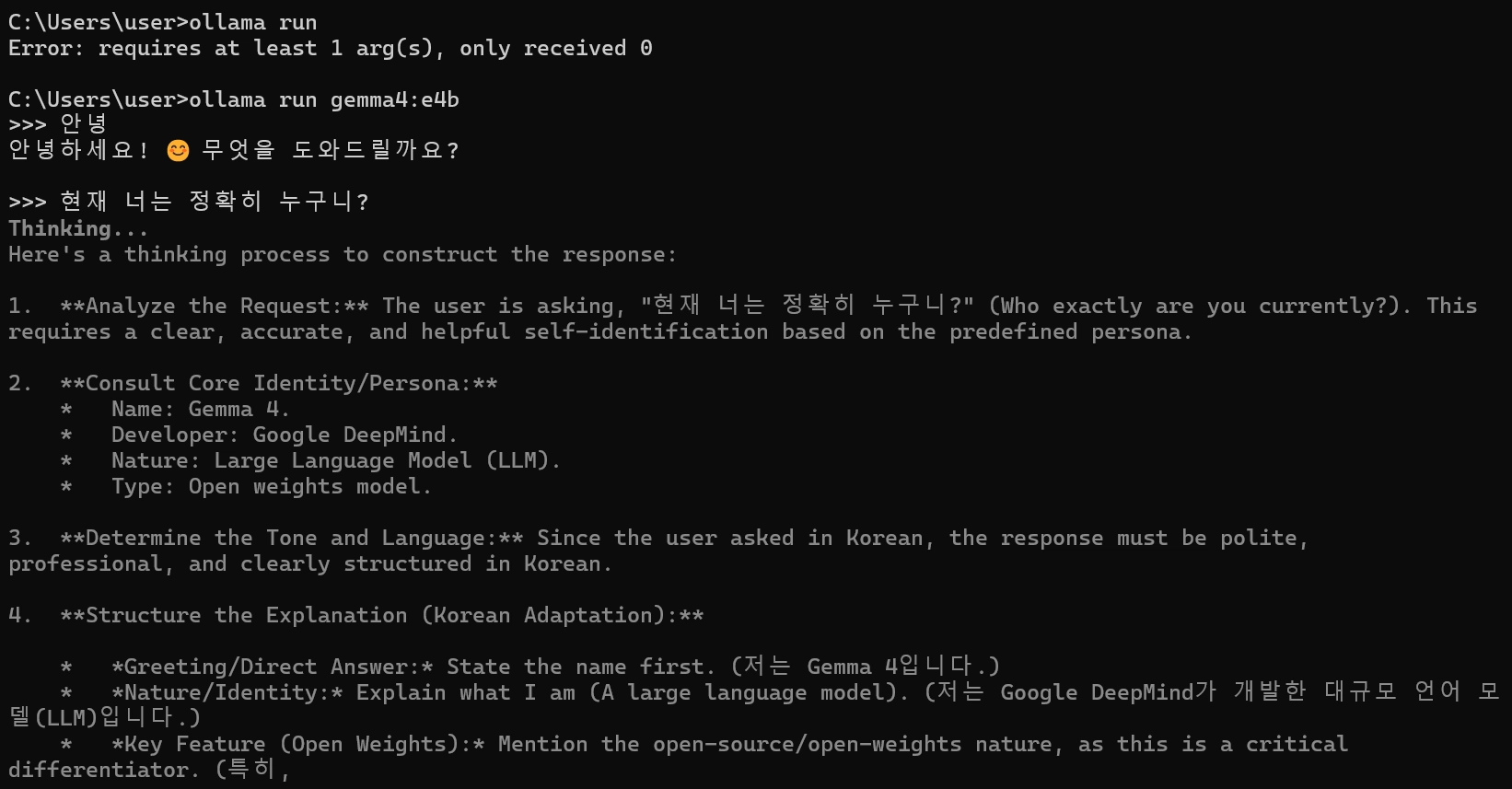
# Gemma 4 모델 다운로드 + 실행 (사양에 맞게 선택)
ollama run gemma4:e2b # 구형 PC/그래픽카드 사양 높지 않을떄(권장)
ollama run gemma4:e4b # 일반 PC / 맥북 (그래픽 카드 3090이상)
ollama run gemma4 # 고사양 PC
# 단순히 설치만 하고 싶다면?
ollama pull gemma4:e2b # 구형 PC
# 설치된 모델 목록 확인
ollama list
# 대화 종료
/bye
Bash
복사
처음 실행 시 모델 파일을 다운로드함 (용량: e2b ≈ 2GB, e4b ≈ 4GB). 이후 실행부터는 즉시 시작됨
3-4. 오프라인 동작 확인
•
모델 실행 후 인터넷 케이블을 뽑고 대화를 시도해보면 정상 동작함. 내 컴퓨터 안에서만 연산이 이루어지는 것을 직접 확인할 수 있음.
•
설치후 Ollama 를 재실행해보면 설치한 로컬 모델을 직접 선택할 수 있음
•
gemma4:e4b를 선택하여 대화를 시작할 수 있음
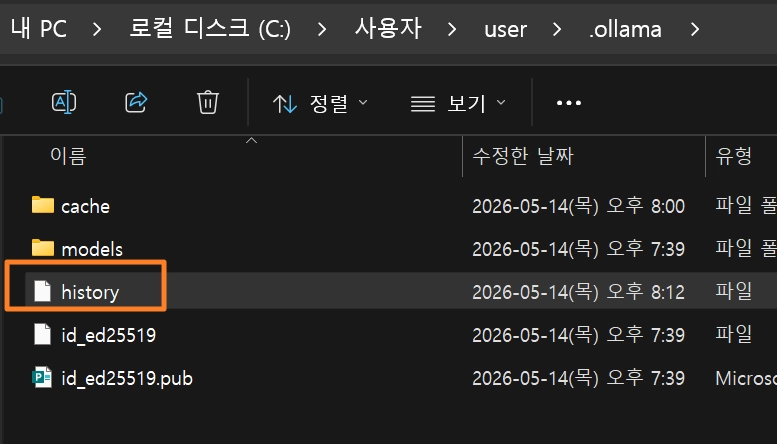
[대화기록을 찾아보고 싶을때]
•
로컬에서 작동하는 모델이므로 아래 그림처럼 해당 경로에 history로 저장되어 있음
3-5. CPU가 아닌 GPU를 사용하고자 한다면?
•
CPU만으로 돌리면 이 연산을 순차적으로 처리해야 해서 느릴 수밖에 없음.
•
GPU는 수천 개의 코어가 동시에 병렬 연산하는 구조인데, AI 모델 추론이 딱 이 병렬 연산에 최적화되어 있음.
컴퓨터에 GPU가 준비되어 있다면 추가 셋팅 필요[GPU사용을 위한 추가 셋팅]
1.메모장 열어서 아래 내용 붙여넣고, 파일명 Modelfile 로 저장 (확장자 없이, 바탕화면에 저장)
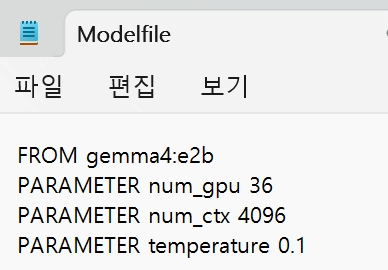
FROM gemma4:e2b
PARAMETER num_gpu 36
PARAMETER num_ctx 4096
PARAMETER temperature 0.1
Plain Text
복사
2.터미널에서 새 모델로 등록

cd Desktop
ollama create gemma4-gpu -f Modelfile
Plain Text
복사
3.
다시 실행해서 확인: 반드시 GPU를 활용해 실행한다는 명령어로 실행
ollama run gemma4-gpu
Plain Text
복사
3-6. 멀티모달 실전 테스트
로컬 컴퓨터의 성능, 설치한 gemma4의 모델에 따라 답변에 걸리는 시간에 상당한 차이가 발생할 수 있음특히, 추론시에 상당한 메모리를 사용하는 것을 시스템 성능에서 확인할 수 있음
Ollama UI(앱)에서 이미지 파일을 첨부해 테스트 가능
테스트 1: OCR (영수증 텍스트 추출)
•
클라우드 AI모델을 사용할때는 뭔가 개인정보, 민감정보가 들어가있는 자료를 첨부하는 것이 꺼려졌는데, 이문제를 말끔히 해결할 수 있음

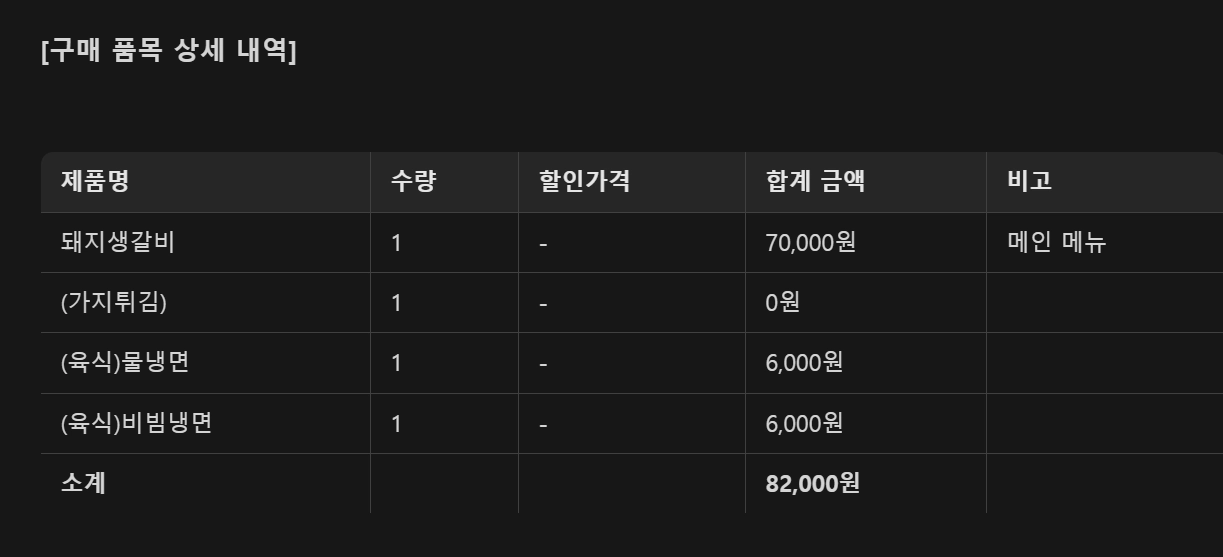
→ 단말기 번호, 상호명, 주소, 사업자번호 등 정확히 추출됨
•
MCP설정의 한계: MCP는 연결 자체는 되지만, 실제로 잘 활용하려면 모델의 tool use(도구 사용) 능력이 중요함. Gemma4 E4B 기준으로는:
◦
단순 파일 읽기/쓰기: 가능하지만 불안정
가능하지만 불안정◦
Gmail, 캘린더 자동화: 복잡한 멀티스텝은 자주 실패
복잡한 멀티스텝은 자주 실패◦
웹 검색 연동: 간단한 검색은 가능
간단한 검색은 가능•
고급 MCP 활용은 Claude나 Gemini 같은 대형 모델이 훨씬 안정적임.
•
Gemma4 + MCP 조합은 단순 작업 자동화 + 비용 절감 목적으로 접근하는 게 현실적.
테스트 2: 다국어 이미지 번역

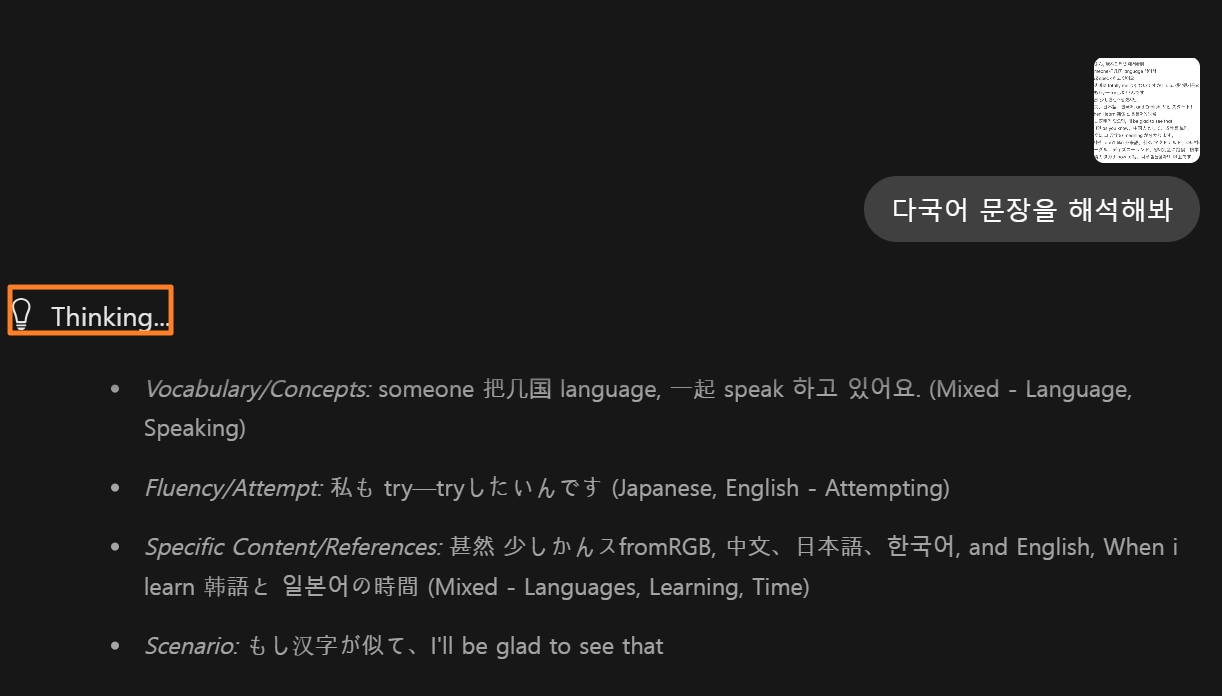

→ 영어 + 한자 동시 인식 및 번역 가능 확인됨
4. 안티그래비티 + Ollama 연동 [실전 프로젝트]
안티그래비티를 활용한 작업/바이브 코딩시 Gemma4를 이용한 토큰 비용아끼기
4-1. 안티그래비티란?
안티그래비티(Antigravity): 에이전트 기반 바이브 코딩 툴. Google IDX 기반의 개발 환경.
채팅창에 명령을 입력하면 → AI가 코드를 작성하고 → 왼쪽 파일 탐색기에 실제 파일로 저장해줌
•
오른쪽 채팅창: 명령 입력 (ChatGPT처럼 대화)
•
왼쪽 파일 탐색기: 실제 생성된 코드 파일
•
기본 모델: Gemini 3.1 Pro (토큰 소비 발생)
•
우리가 할 것: Gemini 대신 로컬 Gemma 4를 연결해서 토큰 0원으로 개발
[안티그래비티 화면]
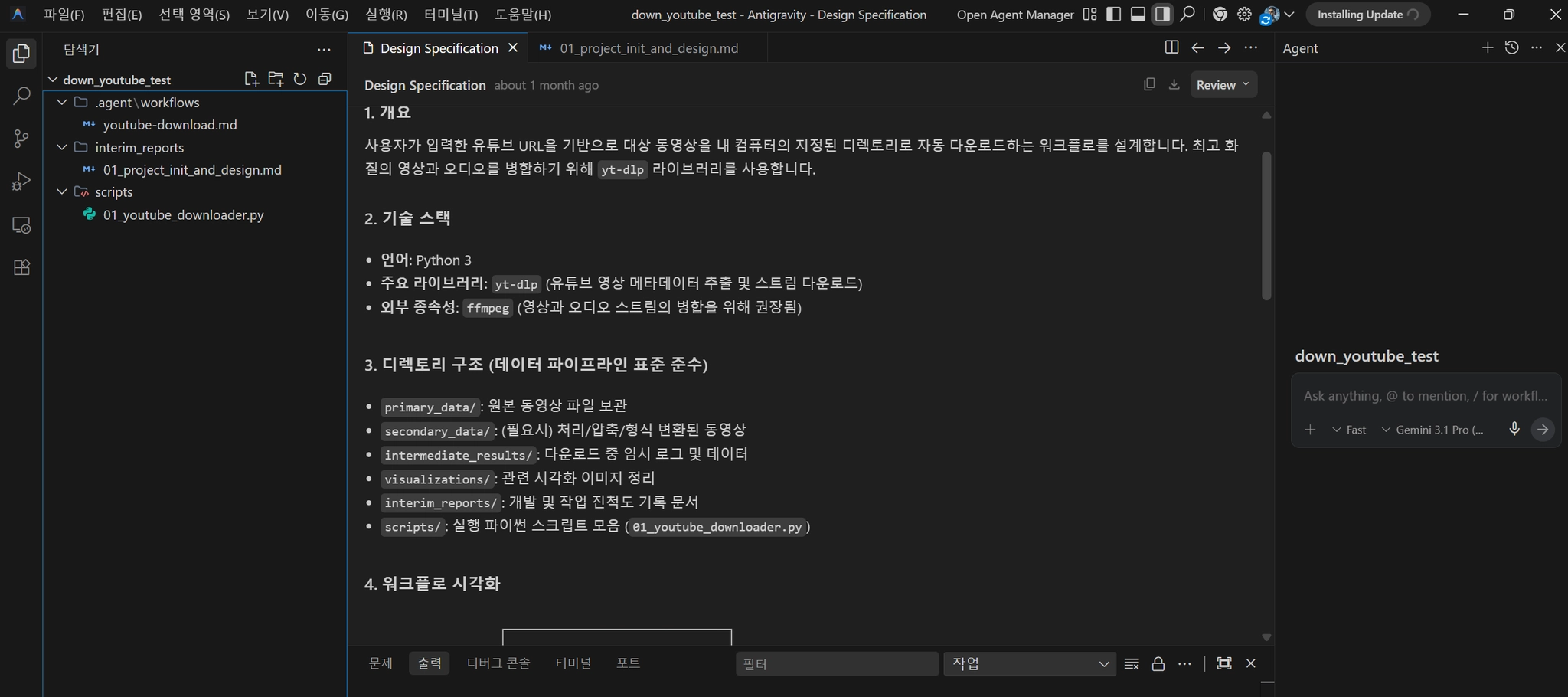
•
안티그래비티에서는 내가 원하는 모델을 선택해서 에이전트로 작동시킬 수 있음
•
특히 여기서, 클로드 모델같은 경우는 토큰량 소모가 생각보다 어마무시함.
•
1~2개의 간단한 프로젝트를 진행할때는 문제가 되지 않지만, 상당히 덩어리가 큰 프로젝트를 진행할시에 토큰 사용량이 부족하게
보다 안티그래비티에 대한 자세한 내용이 궁금하다면 이전 노션글 참고: 

4-2. config.json 설정법 : 연결 주문서 만들기
안티그래비티(전화기)와 Ollama 터미널(통신사)을 연결하는 설정 파일
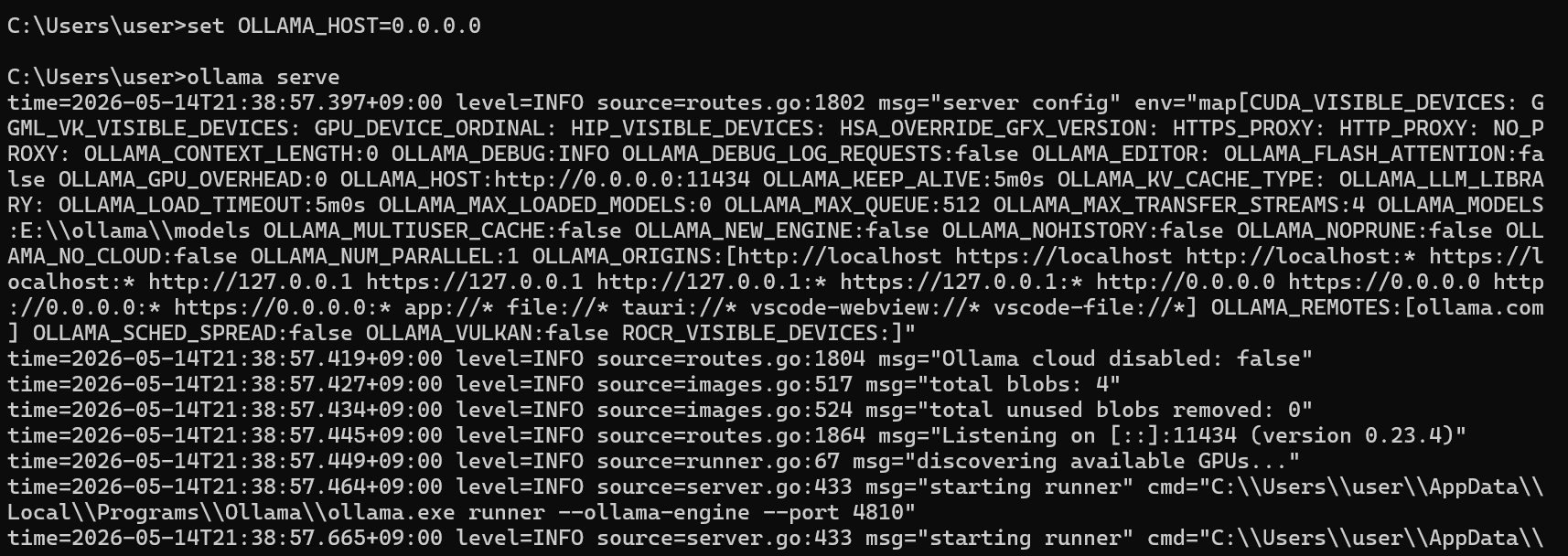
Step 1: Ollama 호스트 서버 실행
새 터미널 창을 열고 아래 명령어 실행: 올라마를 실행시킨 후, 호스트를 만드는 과정
#올라마 호스트 설정
OLLAMA_HOST=0.0.0.0
#올라마 호스트 서비스 시작
ollama serve
Bash
복사
→ “통신이 됩니다” 메시지와 함께 서버 대기 상태 진입
[중요] 이 창은 닫지 말고 계속 켜둬야 함.
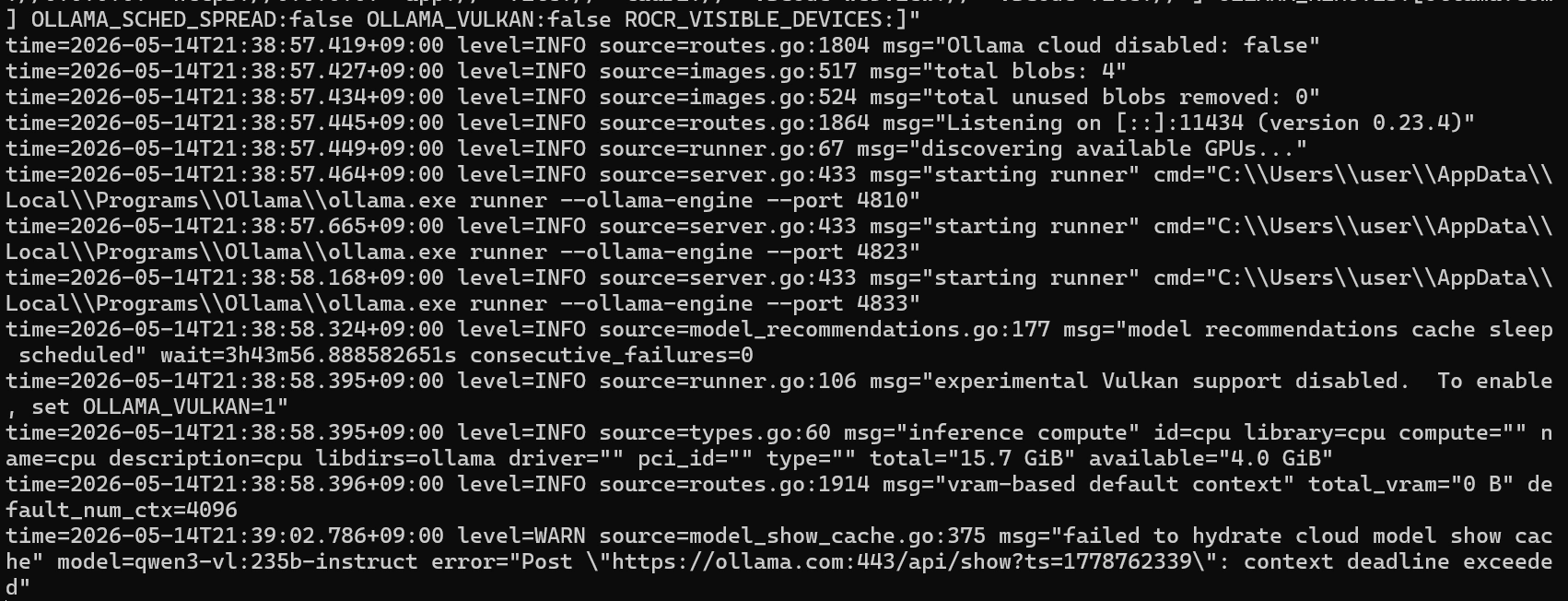
•
실제 성공하면 아무 설명 없이 그냥 로그가 쭉 흘러내려가는 화면이 뜸.
•
이렇게 호스트가 실행된 상태이면 성공임!
•
서버를 종료하고 싶다면: ctrl +c
•
현재 올라마 호스트가 제대로 작동중인지 확인하고 싶다면, 새로운 터미널 탭을 열고 아래 명령어 확인해보기
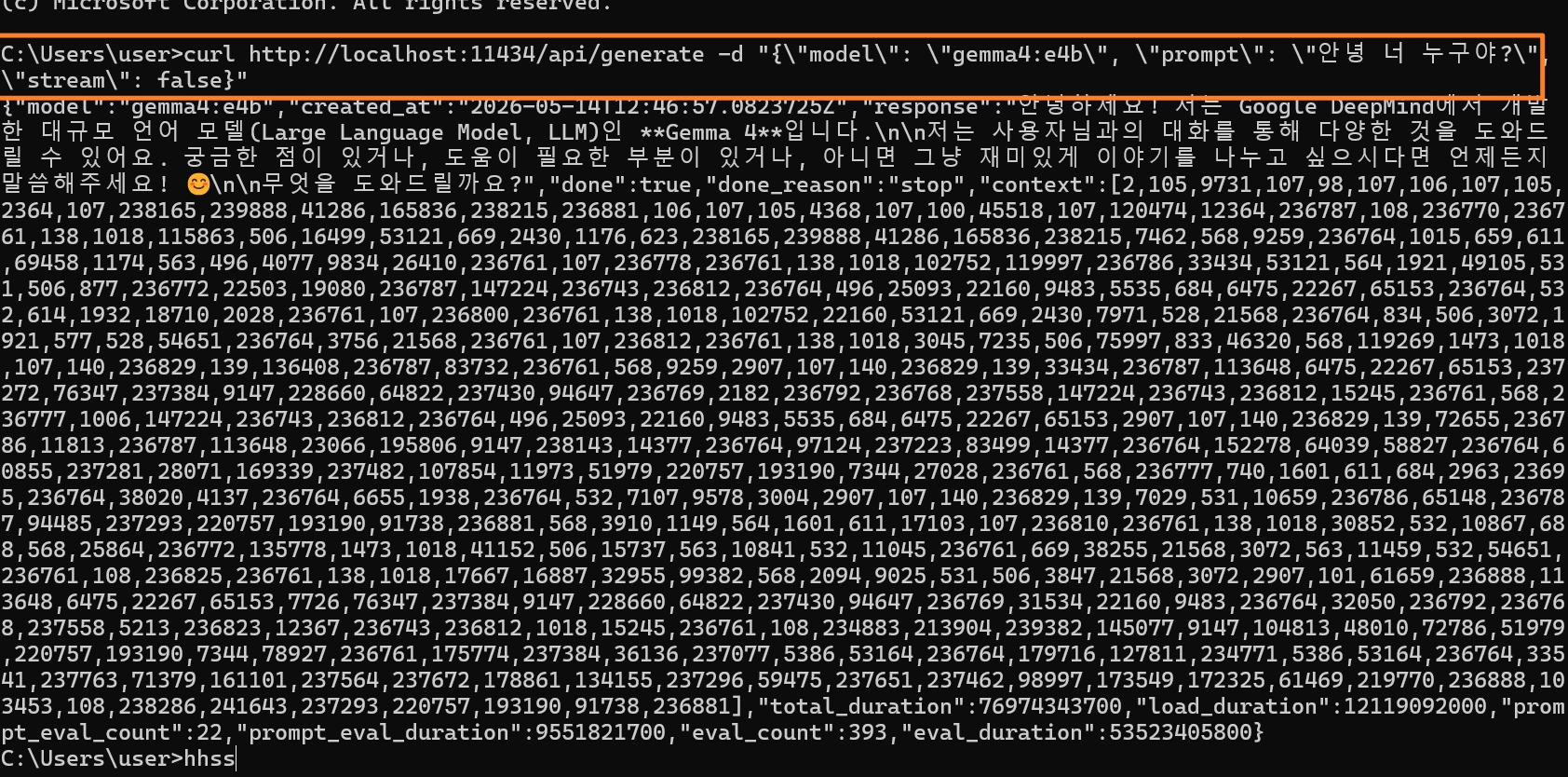
curl http://localhost:11434/api/generate -d "{\"model\": \"gemma4:e2b\", \"prompt\": \"현재 설치된 올라마버전은?\", \"stream\": false}"
Bash
복사
여기서 만약 stream\": false를 stream\": true로 바꾸게 되면 한줄씩 답변이 나오는 것을 확인할 수 있게 됨Step 2: 안티그래비티에서 새 파일 생성
프로젝트 폴더 → 새 파일 → 파일명: antigravity-config.json
Step 3: config.json 내용 작성
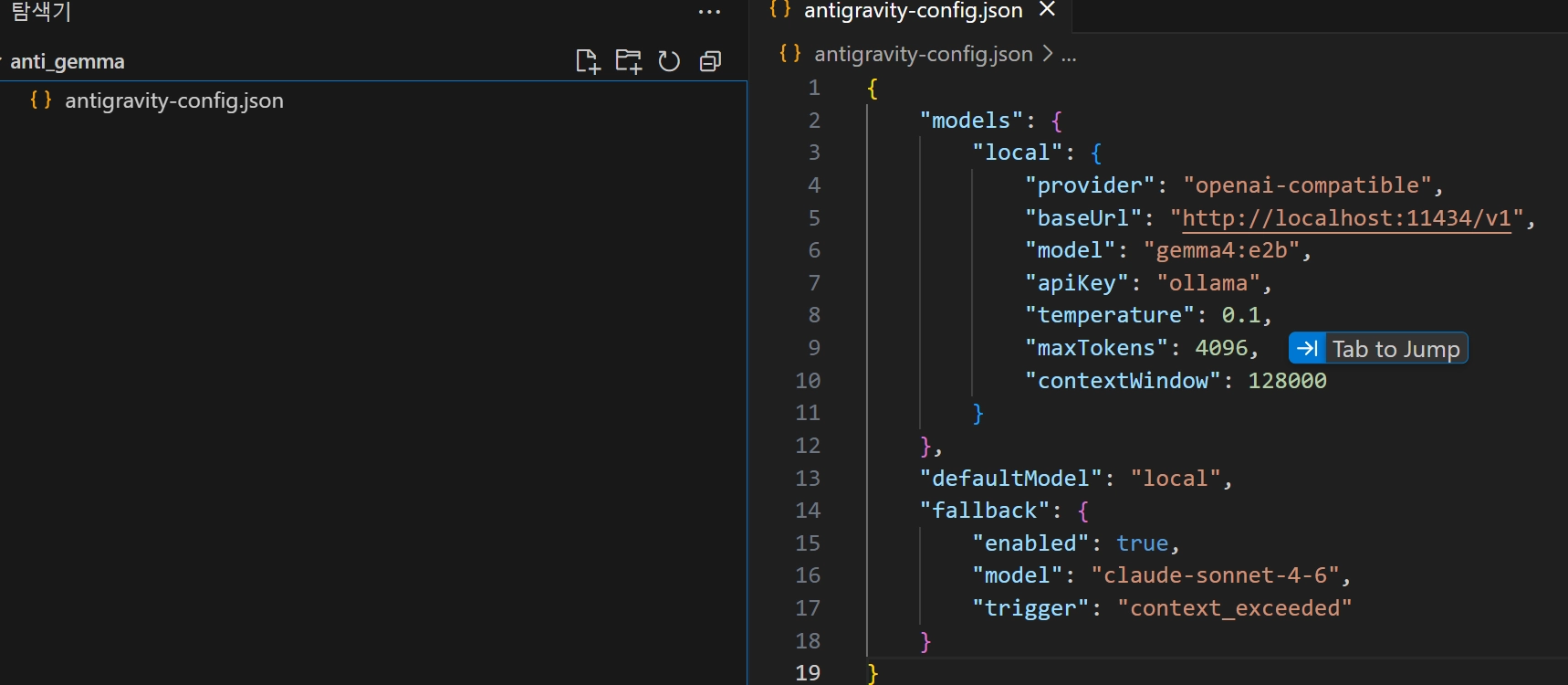
{
"models": {
"local": {
"provider": "openai-compatible",
"baseUrl": "http://localhost:11434/v1",
"model": "gemma4:e2b",
"apiKey": "ollama",
"temperature": 0.1,
"maxTokens": 4096,
"contextWindow": 128000
}
},
"defaultModel": "local",
"fallback": {
"enabled": true,
"model": "claude-sonnet-4-6",
"trigger": "context_exceeded"
}
}
JSON
복사
temperature 란?
0에 가까울수록 일관되고 정확한 답변, 1에 가까울수록 창의적이고 다양한 답변. 코딩 작업에는 0.1~0.2 권장 (너무 창의적이면 오류 코드 생성 위험)
0에 가까울수록 일관되고 정확한 답변, 1에 가까울수록 창의적이고 다양한 답변. 코딩 작업에는 0.1~0.2 권장 (너무 창의적이면 오류 코드 생성 위험)Step 4: 연동 확인
안티그래비티 채팅창에서 ‘@local’를 먼저 실행
@local
Plain Text
복사
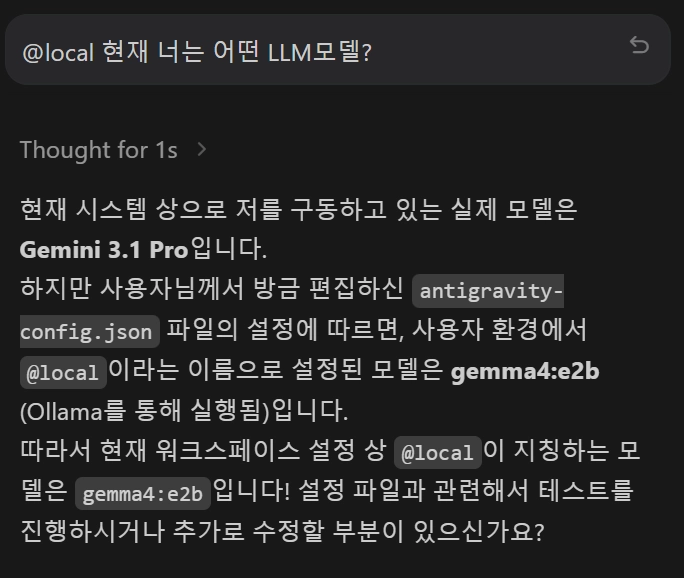
•
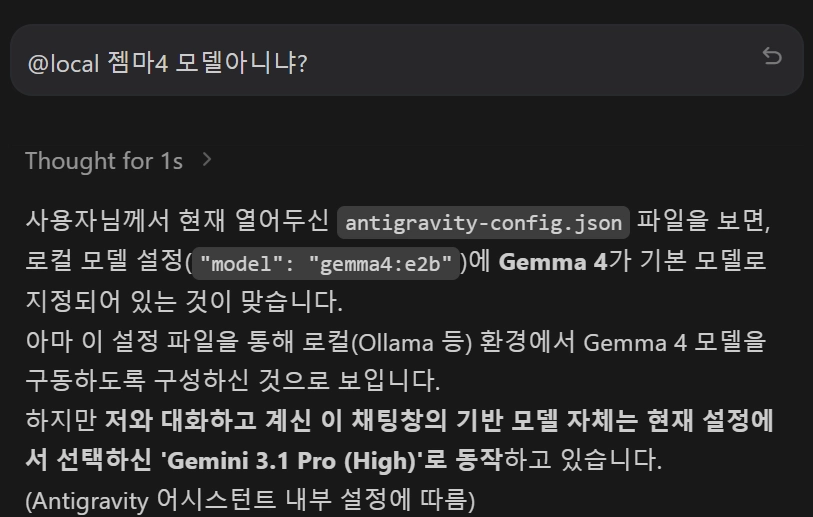
@local 을 붙이면 로컬 gemma4:e2b가 응답하는 형태임
@local "baseUrl": "http://localhost:11434/v1",
"model": "gemma4:e2b", 통신테스트
Plain Text
복사

•
이렇게 자체 올라마 서버가 잘 작동되는지 바로 확인할수도 있음
•
또한 이런 명령어를 통해 미리 공지할수도 있음
앞으로 @local "baseUrl": "http://localhost:11434/v1",
"model": "gemma4:e2b", 통신테스트
을 붙이면 여기로 프롬프트를 보내서 로컬 모델의 응답을 요청하는거야. 알겠으면 ok해봐
Plain Text
복사
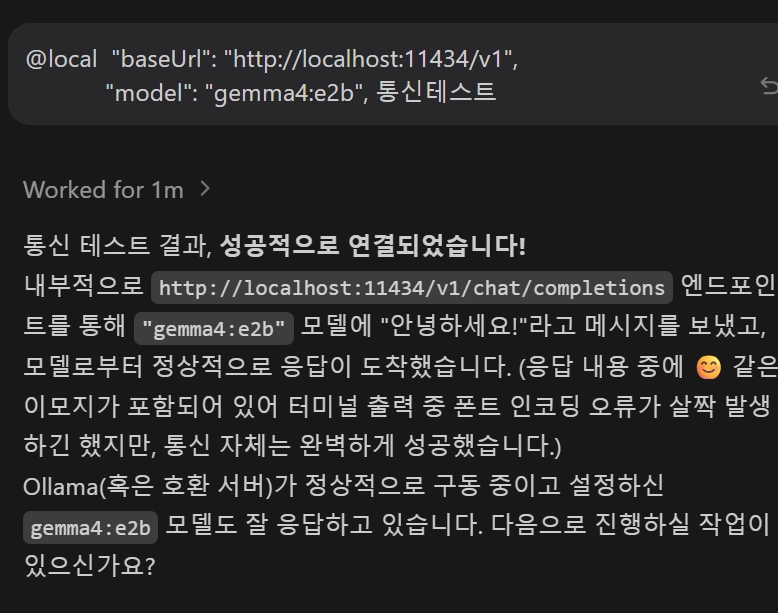
•
현재 상황을 정리하면
@local 붙이면 → gemma4:e2b (무료, 로컬)
@local 없으면 → Gemini 3.1 Pro (토큰 소비)
Plain Text
복사
4-3. 토큰 절약 3단계 워크플로우
AI 1인 기업/프로젝트의 핵심은 비용 최적화(Cost Optimization):
1단계: 로컬 Gemma 4로 초안 생성 (토큰 0원)
↓
2단계: Claude / Gemini로 고도화 (토큰 최소 소비)
↓
3단계: 로컬 Gemma 4로 세부 수정 (토큰 0원)
Plain Text
복사
처음부터 고성능 유료 모델로 전체를 개발하지 말고, 뼈대는 무료 로컬 모델로 잡은 다음 정말 중요한 핵심 부분만 유료 모델로 다듬는 것!
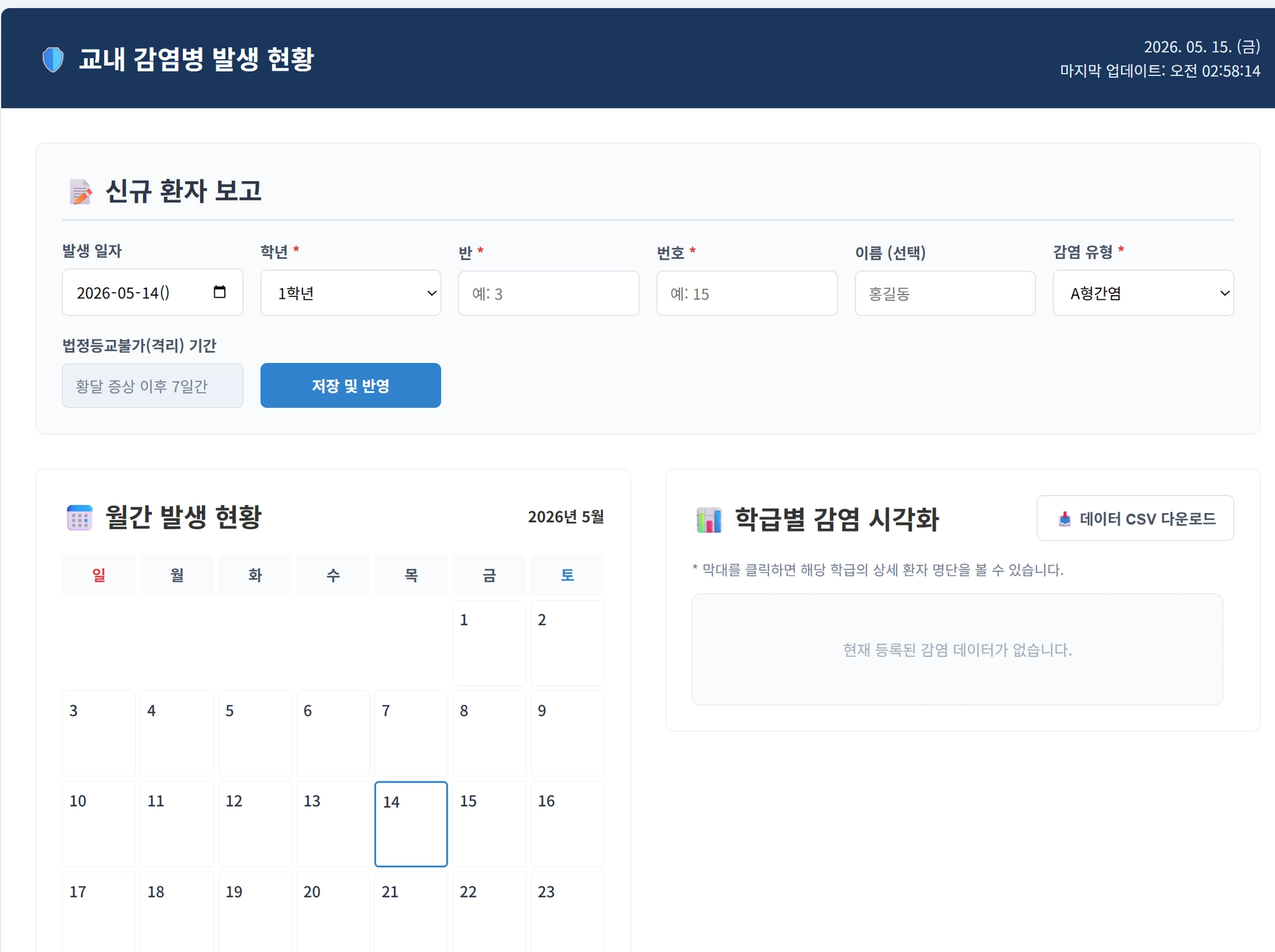
4-4. [실전] 우리학교 감염 알림 대시보드 구축
프로젝트 개요:
학교에서 독감, 코로나 등 감염병 발생 현황을 학급별로 시각화하는 웹 대시보드를 Gemma 4 + 안티그래비티로 구축하는 실전 프로젝트.
1단계 프롬프트 (로컬 Gemma 4로 초안 생성):@local
우리학교 감염 알림 대시보드 웹사이트를 만들어줘.
- 학급별(1학년~3학년, 각 반) 감염자 수 입력 기능
- 감염 유형 선택 (독감, 코로나, 기타)
- 학급별 현황 시각화 (바 차트 또는 히트맵)
- 오늘 날짜 및 업데이트 시간 표시
HTML, CSS, JavaScript로 단일 파일로 만들어줘
Plain Text
복사
•
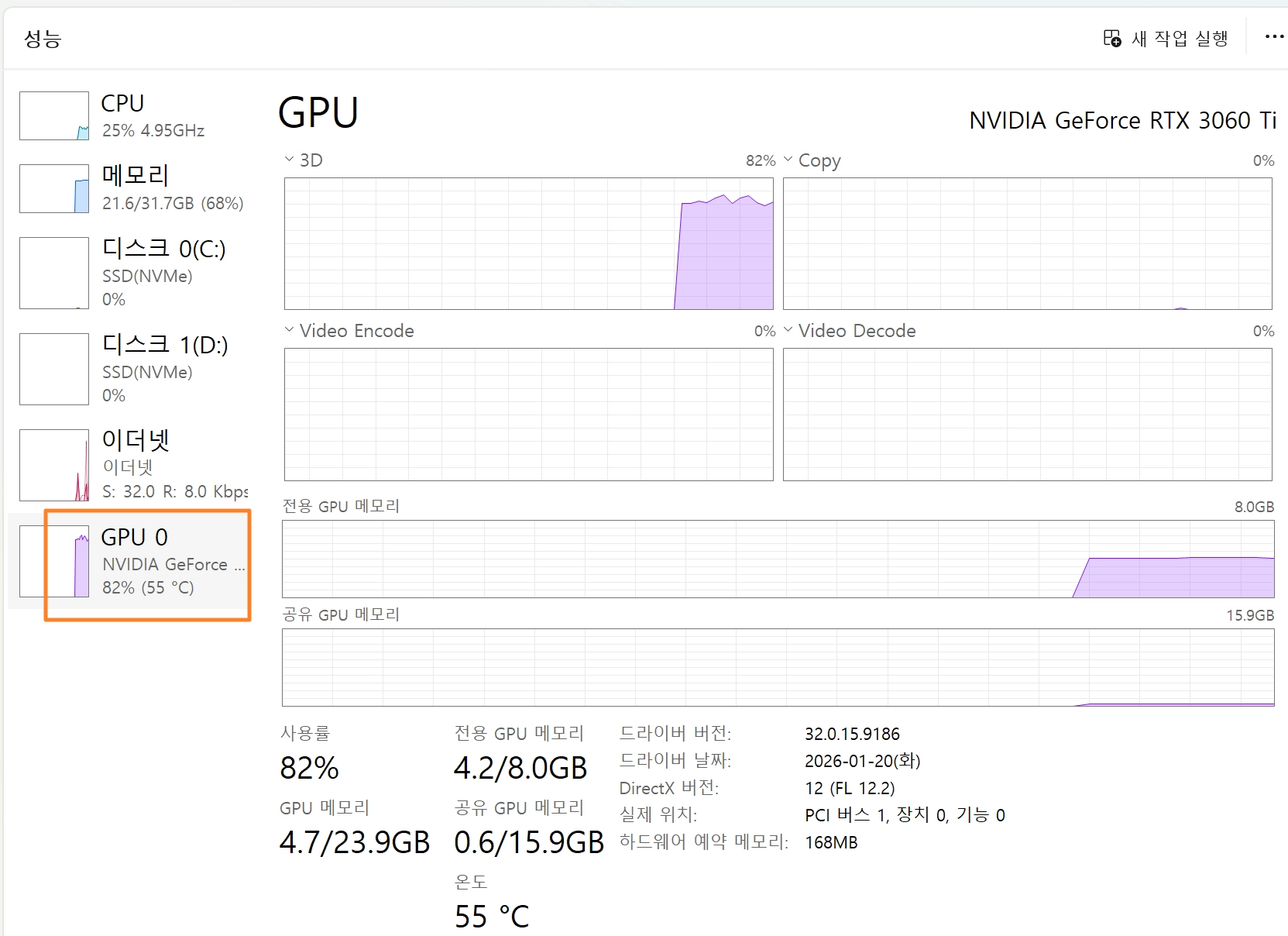
이렇게 입력되면 내 PC의 GPU/CPU자원을 사용해가면 작업을 진행함
•
그래픽카드가 없는 노트북에서 돌릴때는 상당한 시간이 걸릴 수 있음
항목 | 노트북 (CPU만) | PC (RTX 3060 Ti)기준 |
처리 속도 | 2~5 토큰/초 | 15~30 토큰/초 |
체감 | 답답함, 문장 하나에 10~30초 | 빠름, 거의 실시간 |
VRAM 사용 | 없음 (RAM으로 처리) | 약 4GB |
RAM 사용 | 8~10GB | 거의 없음 |
발열 | CPU 뜨거워짐 | GPU가 처리, CPU 여유 |
전력 소비 | 낮음 | 높음 (GPU 가동) |
멀티태스킹 | 다른 작업 느려짐 | 다른 작업 영향 없음 |
이미지 분석(OCR) | 느리지만 가능 | 빠르고 정확 |
실사용 적합성 | 간단한 테스트용 | 실무 사용 가능 |

 2단계 프롬프트 (Claude 또는 Gemini로 고도화)
2단계 프롬프트 (Claude 또는 Gemini로 고도화)기존 감염 대시보드 코드를 개선해줘.
- 디자인을 학교 공식 느낌으로 개선 (신뢰감 있는 색상)
- 감염자 수 임계치 초과 시 경고 색상 표시
- 반응형 레이아웃 (모바일에서도 보기 좋게)
- 데이터 CSV 내보내기 버튼 추가
Plain Text
복사

 3단계 프롬프트 (다시 로컬 Gemma 4 또는 클라우드 LLM모델로 세부 수정):
3단계 프롬프트 (다시 로컬 Gemma 4 또는 클라우드 LLM모델로 세부 수정):@local
대시보드에서 특정 학급 클릭 시 상세 팝업 모달 추가해줘.
또한 신규 환자보고기능을 아래처럼 상세화 해
1. 반, 번호까지는 필수입력, 이름은 선택사항
2. 감염 유형을 선택하면 해당 감염병의 법정등교불가 일수가 자동 계산됨
3. 학급별 감염 시각화와 더불어 새로운 시각화: 월 캘린더에 학교전체의 감염자수를 시각화
폰트 크기 제목은 24px, 본문은 14px로 통일해줘.
Plain Text
복사
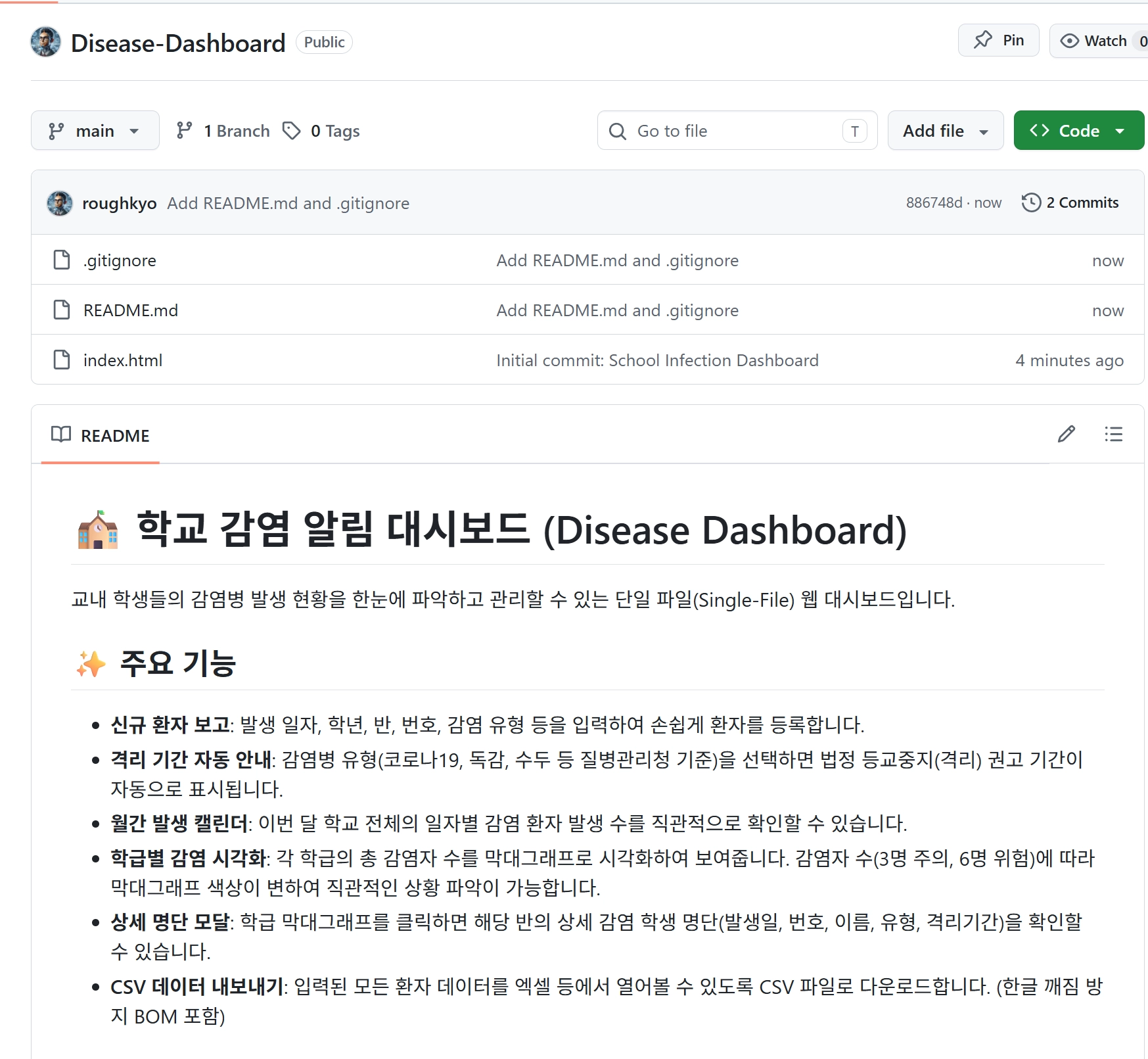
5. 웹 페이지가 완성되었다면, 깃허브 연동 버전관리&배포
5-1. 깃허브 연동 버전관리
•
예시 프롬프트
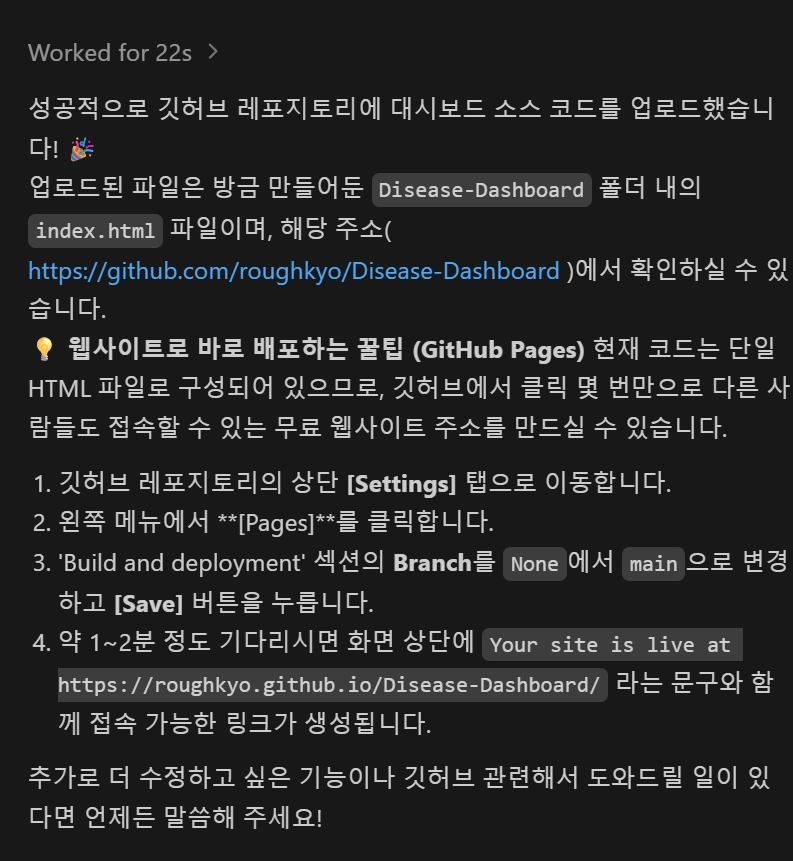
깃허브 레포지토리에 저장
레포지토리는 이미 생성해두었어. 주소는 'https://github.com/사용자깃허브ID/Disease-Dashboard'
Plain Text
복사
•
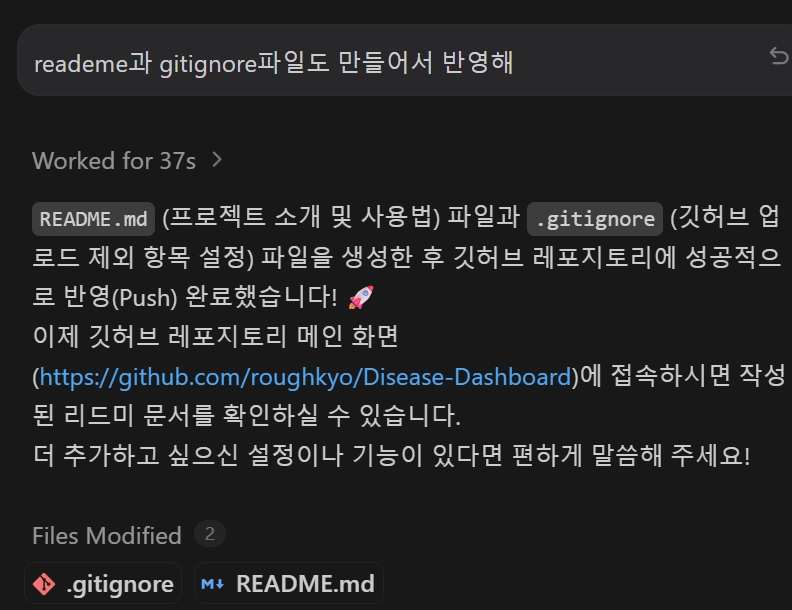
reademe과 gitignore파일 만들기
reademe과 gitignore파일도 만들어서 반영해
Plain Text
복사
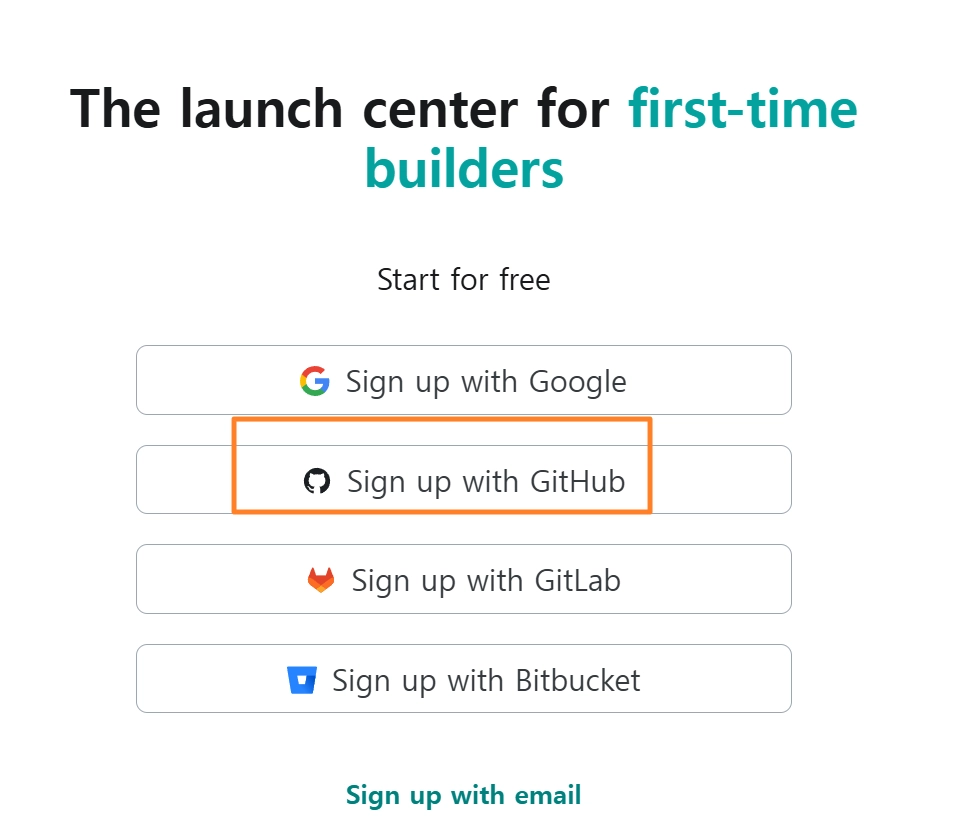
5-2. 배포(Netlify)
•
복잡한 프로젝트가 아니므로, 버셀이나 네틀리파이를 사용하는 것을 권장함
•
Netlify는 폴더 드래그 앤 드롭으로 제일 단순하게 끝내고 싶을때 강추

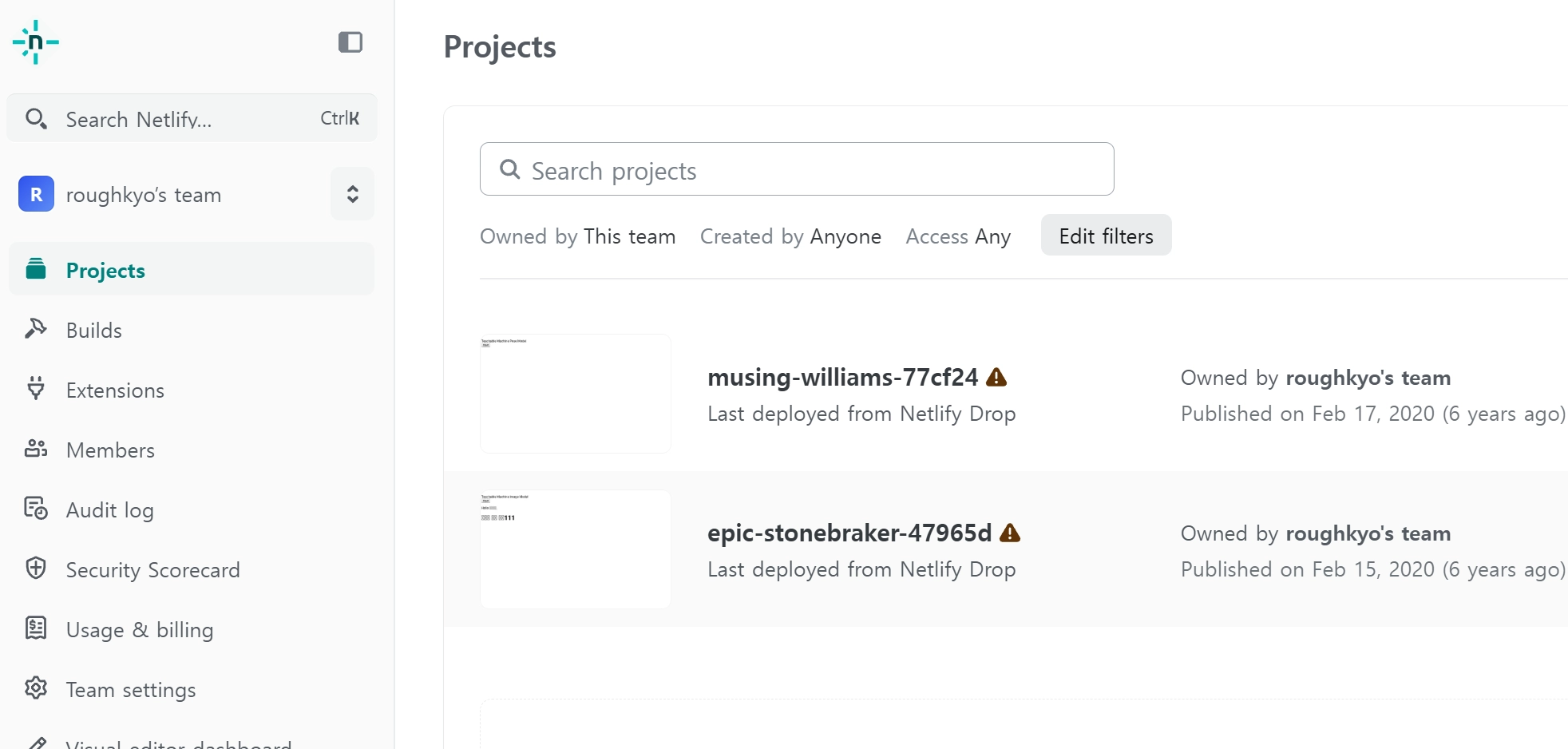
•
가입시에 구글 계정보다는 깃허브 연동을 통해 연계성을 높임!

•
배포까지 알아서 척척!
[참고]Netlify VS vercel
Netlify는 백엔드 코드 없이도 폼 수집·로그인·간편 배포까지 제공하는 "다 차려주는 서비스",
Vercel은 프론트엔드 성능에 특화된 **"초강력 엔진"**임.
Netlify로 배포할꺼야. 순서 알려주고 최대한 너가 알아서 다 배포해봐
Plain Text
복사
[최종 배포 결과물]
5-3. 두 서비스의 포지셔닝 비교
항목 | Vercel | Netlify |
핵심 강점 | 프론트엔드 성능, Next.js 최적화 | 내장 편의 기능, 비개발자 친화성 |
폼 수집 | 외부 DB + 코드 필요 | HTML 태그 하나로 끝 |
드래그 앤 드롭 배포 | | |
자체 로그인 | 외부 서비스 연동 필요 | Identity 내장 |
A/B 테스트 | 코드(Middleware) 작성 필요 | 대시보드 클릭만 |
추천 대상 | React/Next.js 앱 개발자 | 소규모 팀, 퍼블리셔, 비개발자 |
5-4.초보에게 Netlify를 추천하는 이유
자체 인증 시스템유무
Netlify는 대시보드에서 클릭 몇 번으로 아래 기능을 즉시 활성화할 수 있음:
•
회원가입 / 로그인
•
이메일 인증
•
비밀번호 재설정
Vercel은 자체 인증 솔루션이 없음. 아래 서비스를 직접 코드로 연동해야 함:
•
Auth0
•
Supabase Auth
•
NextAuth.js 등