
목차(클릭하세요)

오픈클로, Hermes 모두 사용가능하지만, 오픈클로는 뭔가 꺼림직…
Hermes로 온라인 Agent사용하기의 모든 것
PC 한 대에 Hermes Agent + Ollama 을 올려, 슬랙 하나로 어디서든 3단계 모델 라우팅 AI 에이전트를 무료에 가깝게 운용함
Hermes로 온라인 Agent사용하기의 모든 것
PC 한 대에 Hermes Agent + Ollama 을 올려, 슬랙 하나로 어디서든 3단계 모델 라우팅 AI 에이전트를 무료에 가깝게 운용함[참고자료]


[참고자료]
1. Hermes Agent란 무엇인가?
1-1. OpenClaw vs Hermes Agent
항목 | OpenClaw | Hermes Agent |
주용도 | 24시간 개인 비서·자동화 | 다목적 실험·학습 에이전트 |
실행 환경 | 내 서버/PC (백그라운드) | 터미널 CLI / 메신저 |
LLM 선택 | 다양한 API 연동 가능 | 200개 이상 자유 선택 |
자기 학습 | 메모리·스킬 누적 | 스킬 자동 생성·개선 |
Obsidian 연동 | | 기본 지원 |
보안 risk( 위험도) | 높음 (광범위한 권한) | 중간 |
Windows 네이티브 | 불안정 | Early Beta 지원 |
진입 장벽 | 높음 | 중간 |
OpenClaw와 Hermes는 구조적으로 거의 동일한 아키텍처. Obsidian 연동과 스킬 자동 생성이 Hermes를 선택한 핵심 이유임
나만의 두뇌를 만들기 위한 최적의 서비스!
나만의 두뇌를 만들기 위한 최적의 서비스!•
이걸 쓰고 싶은데, 이게 위험하다니까, 차선책을 찾다보니.. 더 좋은게 얻어걸린 느낌??


•
OpenClaw는 광범위한 도구 통합 기능을 갖춘 생태계 우선 접근 방식을 취하는 반면,
•
Hermes-Agent는 학습 우선 아키텍처를 기반으로 구축
•
OpenClaw는 다양한 도구와 서비스를 조율하는 컨트롤러 역할을 하는 데 중점을 두는 반면,
•
Hermes는 에이전트 자체의 실행 루프에 집중하고 이를 중심으로 시스템을 구축
•
Hermes-Agent의 가장 큰 장점 중 하나는 정교한 메모리 시스템.
◦
OpenClaw의 정적인 메모리 아키텍처와 달리, Hermes는 경험을 토대로 기술과 지식으로 통합하는 동적 메모리 시스템을 구현
1-2. 관련 개념-Tool Calling 루프
Tool Calling 루프 = 일반 LLM에서 Agent로 진화하는 핵심개념•
Agent가 목적을 향해 스스로 계획하고 작동하기 위한 핵심 개념:Tool Calling 루프
•
"LLM이 스스로 도구를 선택하고 실행하는 반복 구조"
•
일반 LLM은 질문 → 답변으로 끝나지만 Tool Calling루프를 포함한 AI Agent는 다름.
[Hermes Agent의 특장점]
Tool Calling 루프 (에이전트의 핵심 개념)
+
메모리 누적 관리
+
멀티플랫폼 게이트웨이 (슬랙, 디스코드 등)
+
스킬 자동 생성·개선
+
Obsidian 연동
+
모델 라우팅 (fallback_providers)
Plain Text
복사
1-3. Windows 설치 가능여부
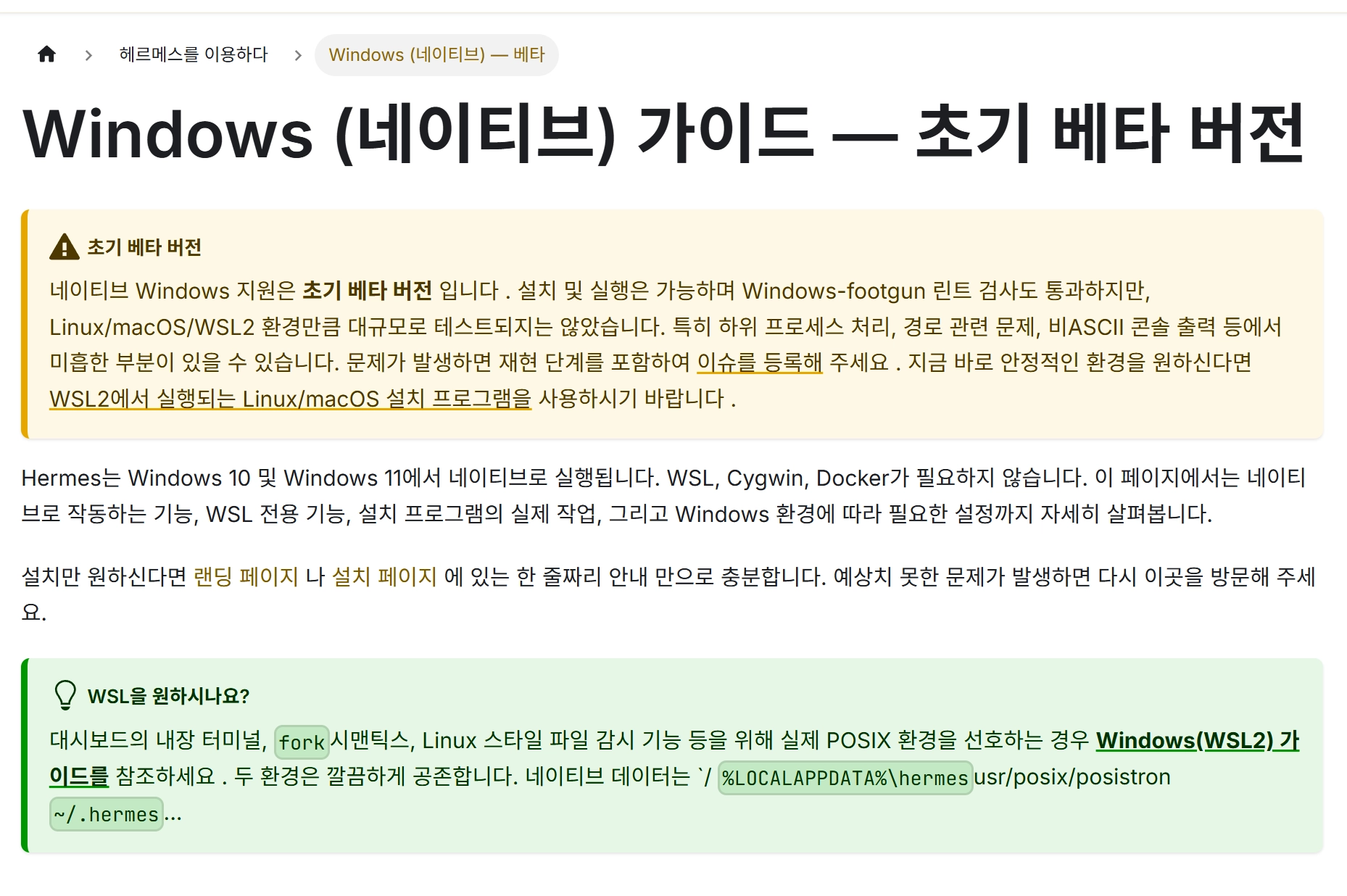
Hermes Agent Windows 네이티브 지원"WSL2, Docker, Cygwin 없이 Windows에서 직접 실행 가능" v0.14.0부터 Early Beta로 공식 지원
v0.14.0부터 Early Beta로 공식 지원•
Hermes Agent는 원래 Linux 기반으로 설계되었으나, v0.14.0(2026.5.16)부터 Windows 네이티브 설치를 공식 지원
•
Early Beta 상태라 WSL2만큼 완전히 안정적이지 않으나, 일반 자동화 용도에서는 충분히 사용 가능
Windows 11
└── Hermes Agent (네이티브 실행)
└── PowerShell로 설치 및 실행
→ 관리자 권한 불필요
→ %LOCALAPPDATA%\hermes\ 에 설치
Plain Text
복사
•
설치는 PowerShell 한 줄로 완료
iex (irm https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.ps1)
PowerShell
복사
•
설치 후 새 터미널 열고 확인:
hermes --version
PowerShell
복사
•
Ollama도 Windows 네이티브 지원이라 둘 다 WSL2 없이 Windows에서 직접 실행
[네이티브 vs WSL2 기능 비교]
기능 | Windows 네이티브 | WSL2 |
CLI / 메시징 게이트웨이 | | |
슬랙 Socket Mode | | |
로컬 Ollama 연동 | | (네트워킹 경유) |
대시보드 내장 터미널 | (POSIX PTY 필요) | |
로그인 시 자동 시작 | (schtasks) | (systemd) |
안정성 | Early Beta | 안정적 |
1-4. 슬랙 계정이 필요한 이유
[참고] Hermes Agent 공식 지원 메신저: Hermes 를 작동시키려면 메신져가 필요
학교망 기준: 슬랙이 유일한 방법
•
슬랙 하나로 학교·집·폰 모두 통일. 별도 웹 대시보드 불필요
메신저 | Hermes 지원 | 학교망 |
슬랙 | | 사용 가능 확인 |
디스코드 | | 차단 |
텔레그램 | | 차단 |
카카오톡 | | |
2. 최종 아키텍처
2-1. 전체 구조도
슬랙 (학교 ✅ / 집 ✅ / 스마트폰 ✅)
↓
Socket Mode (WebSocket, 공개 URL 불필요)
↓
데스크톱 Windows (네이티브)
└── Hermes Agent
├── 단순 작업 → Gemma 4 E2B (Ollama 로컬, 무료)
├── 중간 작업 → Gemini 3.1 Flash-Lite API (무료 티어 소진 후 유료)
└── 복잡 작업 → Gemini 3.5 Flash API (무료 티어 소진 후 유료)
↓
Obsidian Vault
(LLM 사용 기록 자동 저장)
Plain Text
복사
2-2. 3단계 모델 라우팅
•
1단계는 로컬LLM을 사용, 2단계는 Gemini 3.1모델 호출, 3단계는 Gemini3.5 모델 호출
단계 | 모델 | 용도 | 비용 |
1단계 | Gemma 4 E2B (로컬) | 분류, 짧은 요약, 단순 응답 | 전기세만 |
2단계 | Gemini 3.1 Flash-Lite | 데이터 처리, 자동화 실행 | 무료 티어 |
3단계 | Gemini 3.5 Flash | 깊은 추론, 멀티스텝 에이전트 | 무료 티어 소진 후 유료 |
모델 선택 판단은 Hermes가 자동으로 수행. fallback_providers 설정으로 우선순위 지정함
2-3. PC 상태별 폴백 전략
PC 켜져있을 때 (평상시)
├── 단순 → Gemma 4 E2B 로컬 (비용 0원)
├── 중간 → Gemini 3.1 Flash-Lite (무료 티어 소진 후 유료)
└── 복잡 → Gemini 3.5 Flash (무료 티어 소진 후 유료)
PC 꺼졌을 때 (재부팅 / 점검)
├── 로컬 모델 없음 → 자동 감지
├── 단순 → Gemini 3.1 Flash-Lite로 자동 대체
└── 복잡 → Gemini 3.5 Flash
Plain Text
복사
Hermes fallback_providers 설정 한 번으로 자동 전환됨. 별도 코드 불필요
터널은 속도에 영향 없음. 보안만 강해지는 구조
3. 설치 스택 및 순서
3-1. 설치 목록
도구 | 설치 방법 | 역할 |
Hermes Agent | PowerShell 한 줄 설치 | 에이전트 루프 전체 |
Ollama (Windows 네이티브) | exe 설치 | 로컬 LLM 실행 |
Gemma 4 E2B | ollama pull gemma4:e2b | 로컬 추론 모델 |
Obsidian | exe 설치 | 대화 기록 저장 |
3-2. 권장 설치 순서 (5+1단계)
1단계: Ollama 설치 + Gemma 4 E2B 다운로드
→ 로컬 LLM 첫 실행 경험
→ 터미널에서 직접 대화 테스트
2단계: Hermes Agent Windows 네이티브 설치
→ PowerShell에서 설치 스크립트 실행
→ 새 터미널 열고 hermes --version 확인
3단계: Hermes Agent 세팅
→ 슬랙 앱 생성 + Socket Mode 활성화
→ SLACK_BOT_TOKEN, SLACK_APP_TOKEN 발급
→ Hermes 설정 파일에 토큰 입력
→ 슬랙에서 첫 에이전트 대화 확인
4단계: Gemini API 연동 테스트
→ Google AI Studio에서 API 키 발급 확인
→ Flash-Lite 호출 테스트
→ 3.5 Flash 호출 테스트
→ API 키 정상 작동 여부 점검
5단계: Hermes Agent 3단계 모델 라우팅 + fallback 설정
→ Hermes 설정 파일에 providers 순서 지정
1순위: Gemma 4 E2B (Ollama 로컬)
2순위: Gemini 3.1 Flash-Lite
3순위: Gemini 3.5 Flash
→ fallback_providers 설정 완료
→ PC 켜짐: E2B 로컬 우선 실행 확인
→ PC 꺼짐: Flash-Lite 자동 대체 확인
→ 3.5 Flash 자동 전환 테스트
6단계: Obsidian 연동
Plain Text
복사
4.Hermes Agent 세팅
Hermes Agent를 Windows 네이티브로 설치하고, 슬랙 Socket Mode로 첫 연동을 완료함
[참고]
4-1. Hermes Agent 설치
•
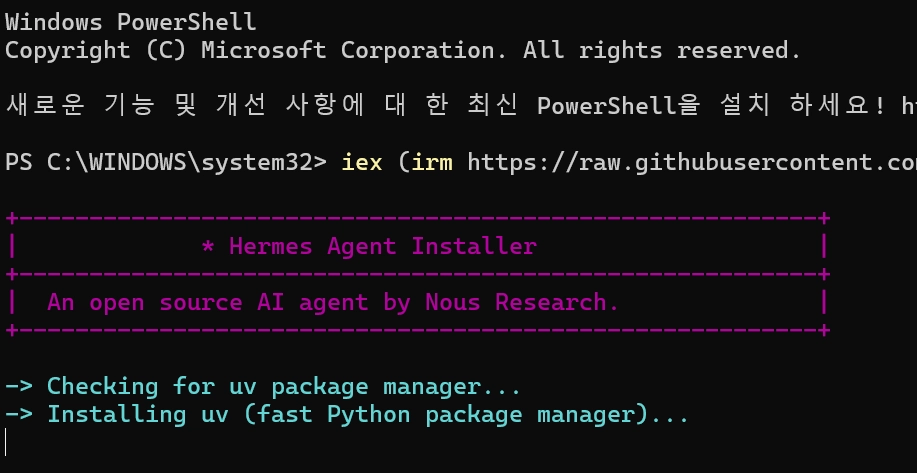
Windows 네이티브 설치: PowerShell에서 한 줄로 완료
•
관리자 권한까지 푤요 없음, %LOCALAPPDATA%\hermes\ 에 설치됨
•
설치가 완료되면 ‘hermes' 를 검색해보기
# PowerShell에서 실행
iex (irm https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.ps1)
PowerShell
복사
•
참고로 uv, Python 3.11을 설치하고 저장소를 클론하여 모든 것을 설정해줌
•
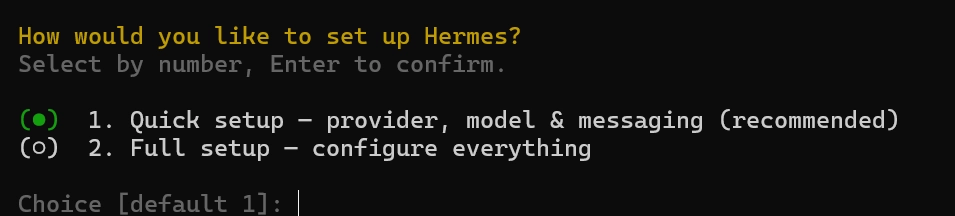
관련 라이브러리를 한꺼번에 모두 설치해주는 모습, 설치가 완료되면 Quick setup으로 먼저 기본 세팅하고, 나중에 세부 조정하기
•
gemini API키를 연계할 목적이므로 15번만 선택하기

•
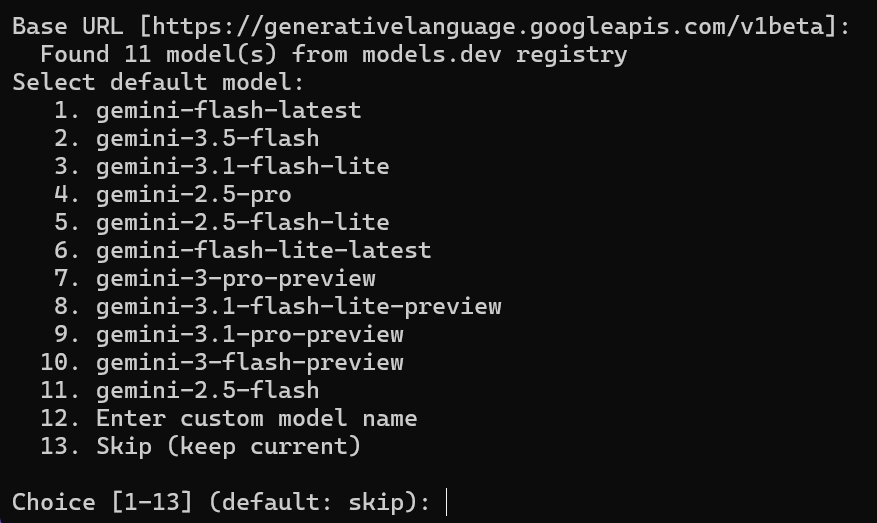
Base URL은 건드릴 필요없음 사용할 제미나이 모델을 선택 후
사용할 제미나이 모델을 선택 후 Base URL = Gemini API 서버 주소
기본값: https://generativeai.googleapis.com/v1beta
→ 일반 사용자는 바꿀 필요 없음
→ 기업용 프록시나 커스텀 엔드포인트 쓸 때만 변경
Bash
복사

•
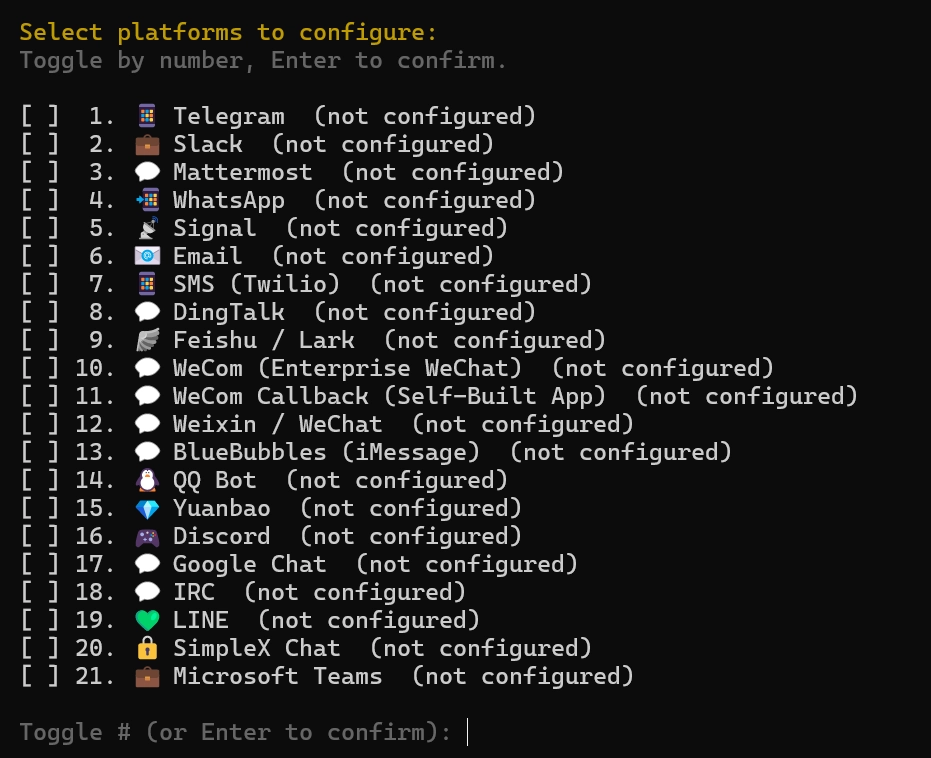
로컬에서 실행할 예정이므로 여기서는 7번 선택 슬랙연동을 진행해야 하니 ‘messaging’선택
슬랙연동을 진행해야 하니 ‘messaging’선택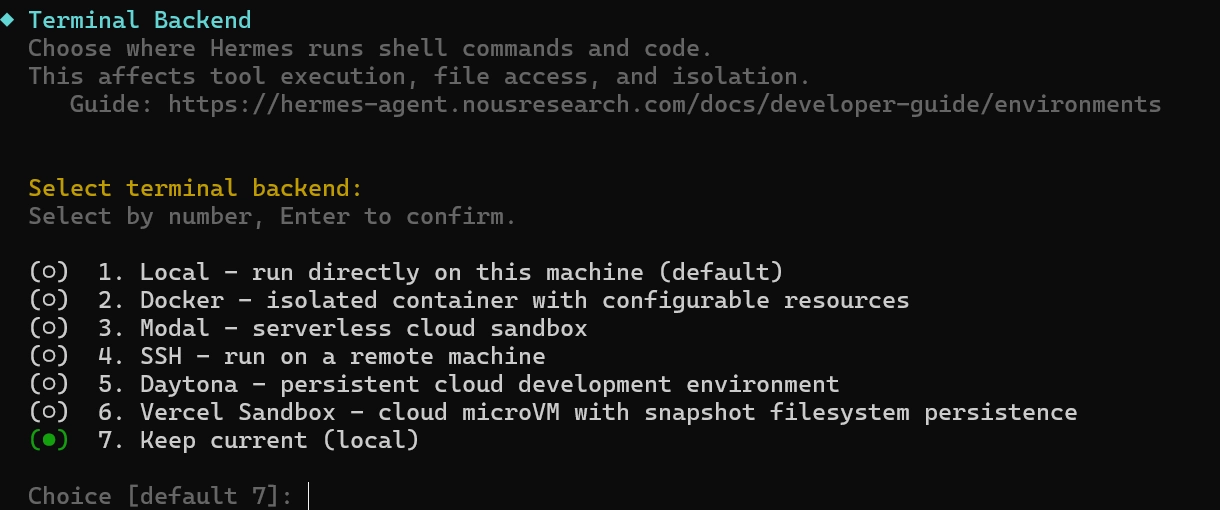
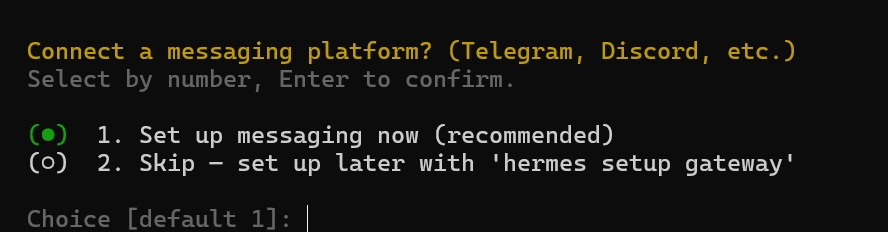
•
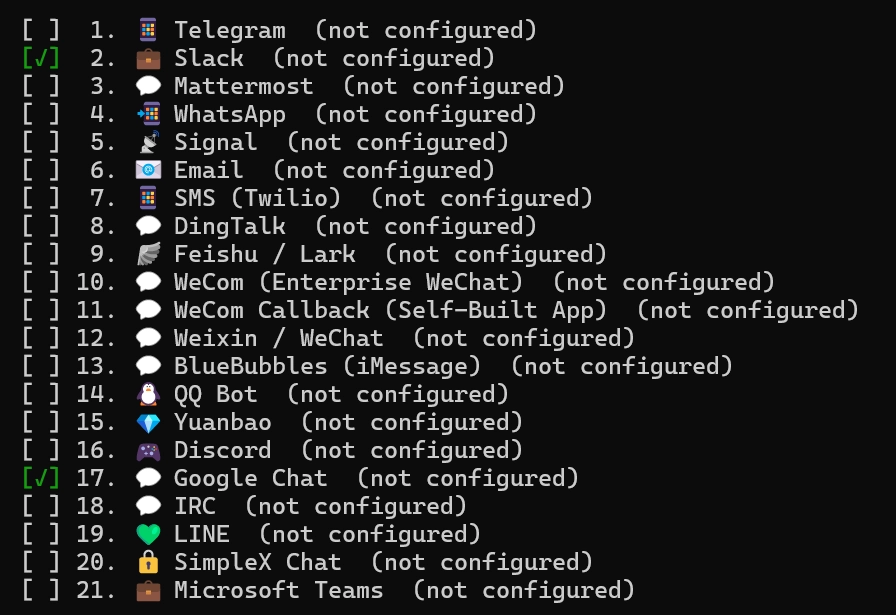
이후 슬랙과 구글챗을 순서대로 선택하기, 2번 enter, 17번 enter
•
설치 완료 후 새 터미널 열고 확인
hermes --version
PowerShell
복사
4-2. 슬랙 앱 생성 + Socket Mode 활성화
[1단계]슬랙 앱 생성 순서
•
참고로 슬랙의 워크스페이스에서 채널이 ‘공개’채널이여야 나중에 챗봇이 작동을 잘함
1. https://api.slack.com/apps 접속
2. Create New App → From a manifest
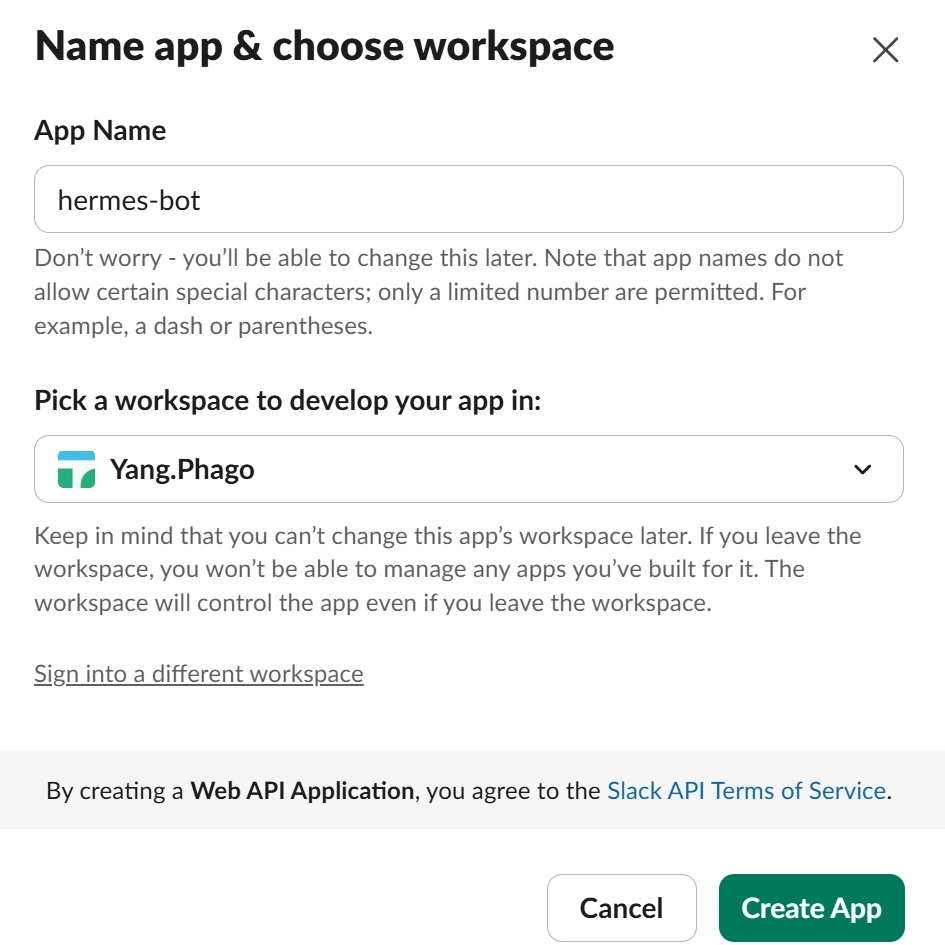
3. 앱 이름 입력 (예: hermes-bot)
4. 워크스페이스 선택 → Create App
Plain Text
복사
•
From a manifest: 설정 파일을 붙여넣으면 자동으로 세팅
•
From scratch: 하나하나 수동으로 설정
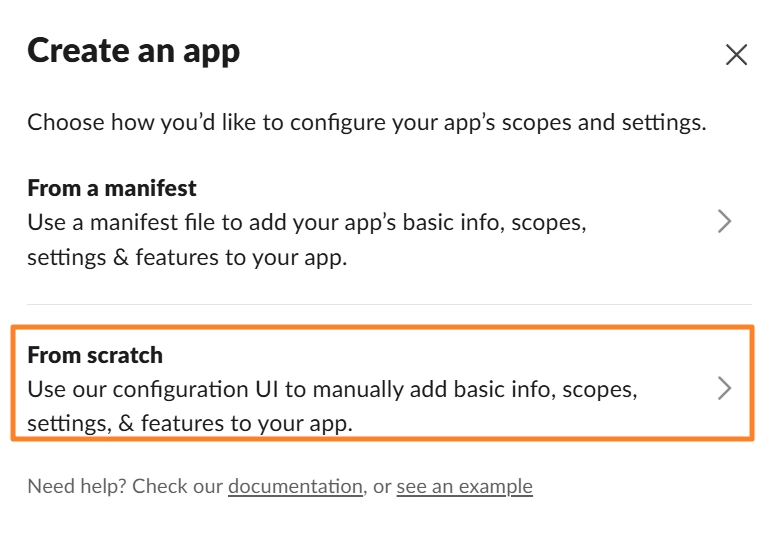
•
이후 App name과 워크 스페이스 선택
•
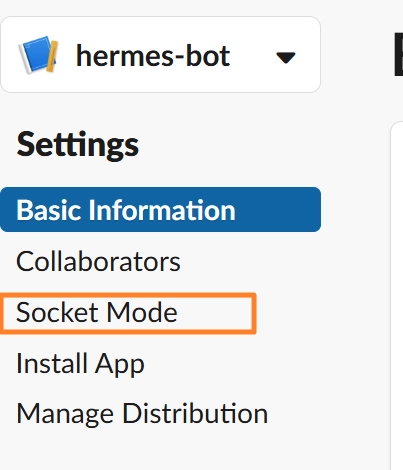
왼쪽의 Settings → Socket Mode → Enable Socket Mode
활성화
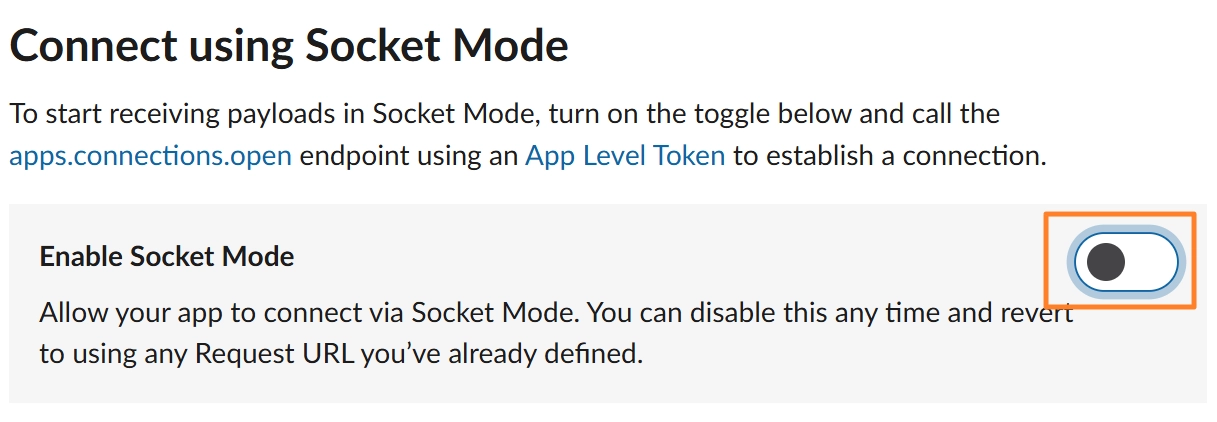
[2단계]Socket Mode 활성화방법
Settings → Socket Mode → Enable Socket Mode ✅
→ App-Level Token 생성
→ 이름 입력 (예: hermes-socket)
→ connections:write 권한 추가
Bash
복사
•
xapp- 로 시작하는 토큰을 복사하기 (SLACK_APP_TOKEN)
[3단계]Bot Token 발급과정
•
왼쪽에서 Features → OAuth & Permissions 선택 → Bot Token Scopes 추가
•
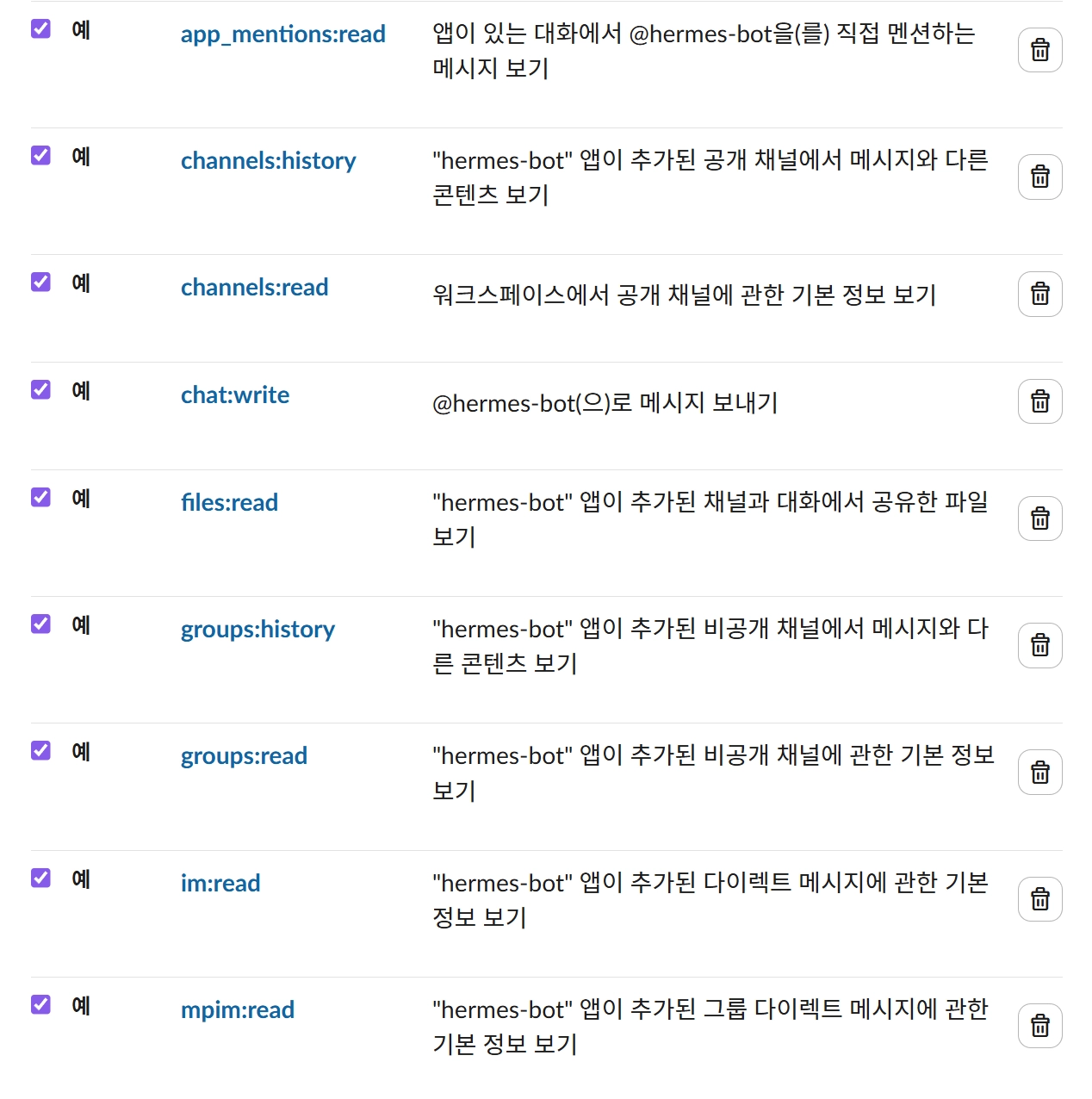
봇 토큰 범위 → OAuth 범위 추가 클릭해서 아래 5개 추가
•
페이지 위로 올라가서 Install to Workspace 버튼 클릭
•
여기서 만들어진 Bot User OAuth Token 복사
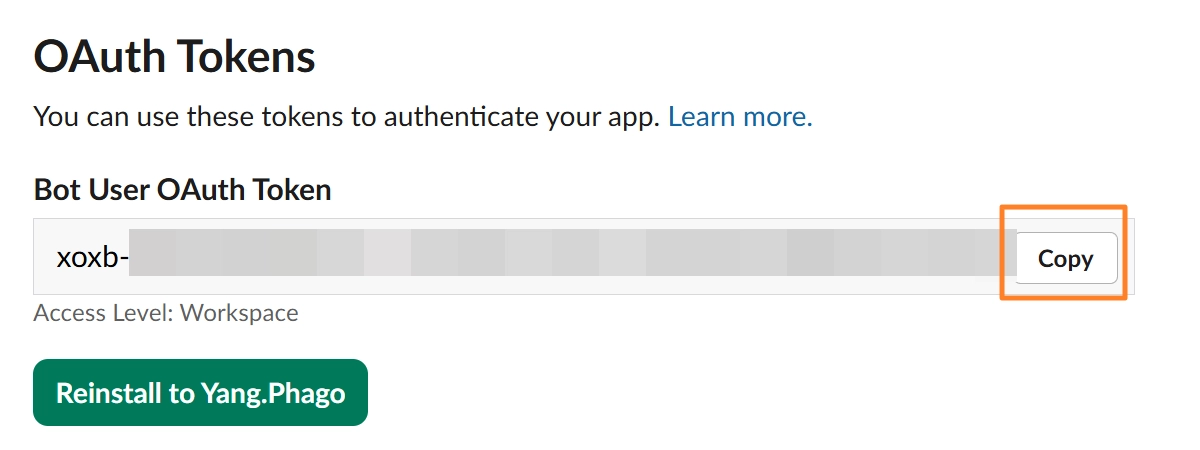
[4단계]Event Subscriptions활성화
•
Subscribe to Bot Events: app_mention 추가
•
message.channels 추가
•
마지막으로 Save Changes
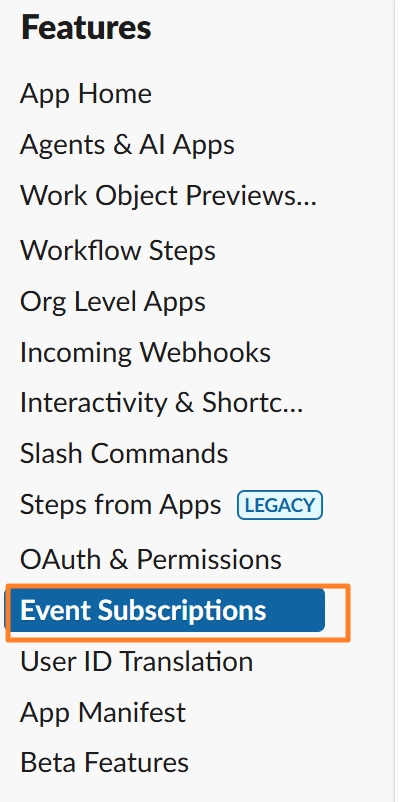
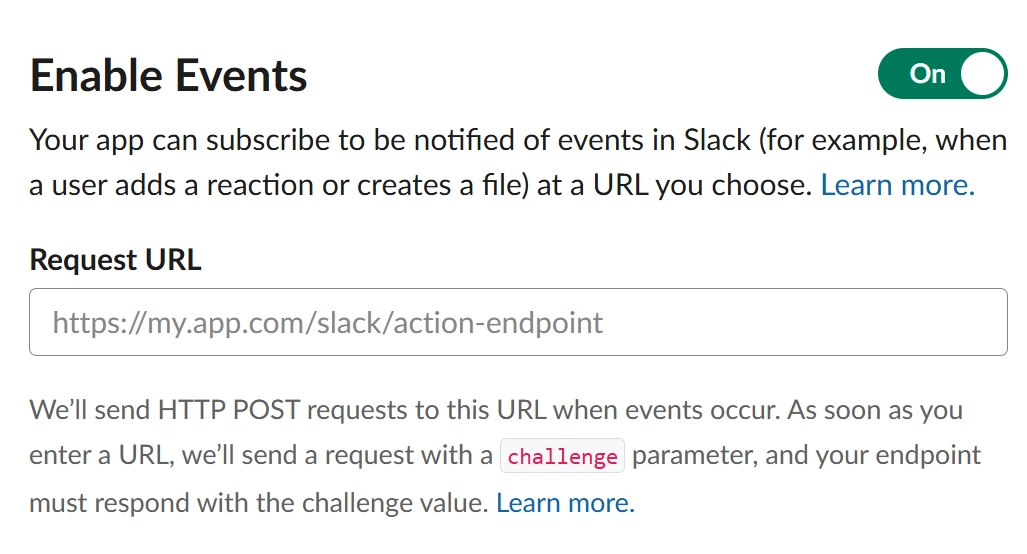
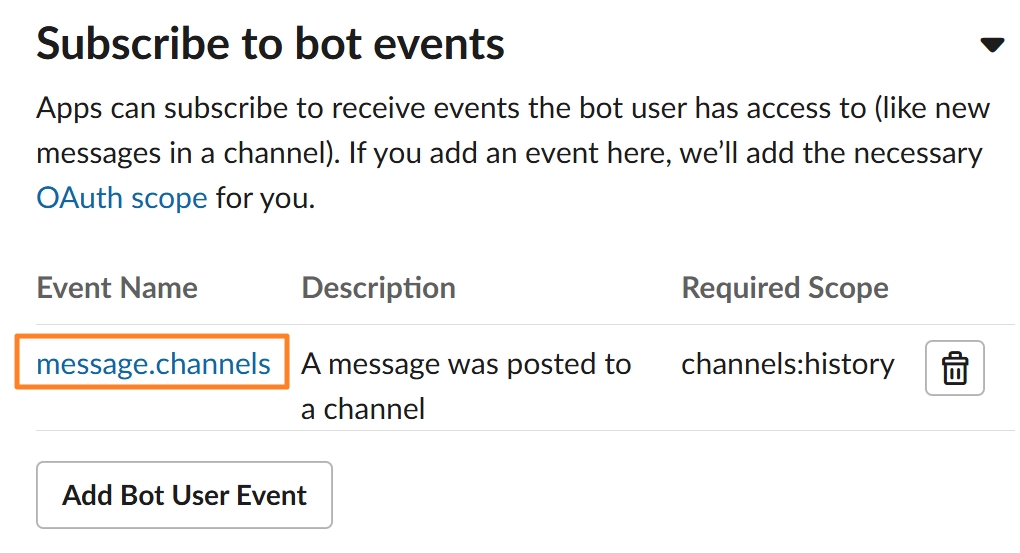
4-3. 터미널에서 Hermes 설정 파일에 토큰 입력
•
마찬가지로 토큰키이므로 화면에 드러나지 않게 됨
•
토큰을 입력하면 설치된 헤르메스 폴더안의 config.yaml파일에 그 정보가 저장되는 방식

# %USERPROFILE%\.hermes\config.yaml
platforms:
slack:
enabled: true
bot_token: "xoxb-your-bot-token"
app_token: "xapp-your-app-token"
YAML
복사
•
설치 후 마지막에 PC부팅시 자동시작을 위해 y입력 gateway 실행하기 그뒤 대부분 y선택
gateway 실행하기 그뒤 대부분 y선택

•
최종적으로 Hermes Gateway설정이 완료되었다는 메시지를 보면 됨!

4-4. 첫 에이전트 대화 확인
# Hermes 실행
hermes gateway start
Bash
복사

0.
슬랙 패키지 설치하기
•
헤르메스 에이전트가 설치된 폴더로 이동한 다음
•
파워셀에서 명령어 입력
pip install 'hermes-agent[slack]'
Bash
복사
•
이후 hesmesgateway 재시작
hermes gateway restart
Bash
복사
1.슬랙에서 채널 하나 선택 (또는 새 채널 생성)

2 .채널에 hermes-bot 초대
→ /invite @hermes-bot 입력
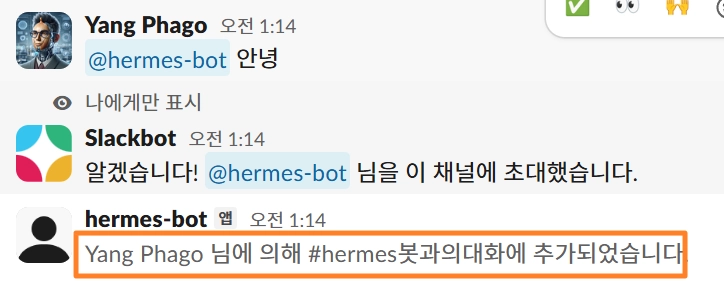
3.
채널에서 멘션
→ @hermes-bot 안녕
# 슬랙에서 봇 멘션
@hermes-bot 안녕
→ 응답 오면 연동 성공 ✅
Bash
복사
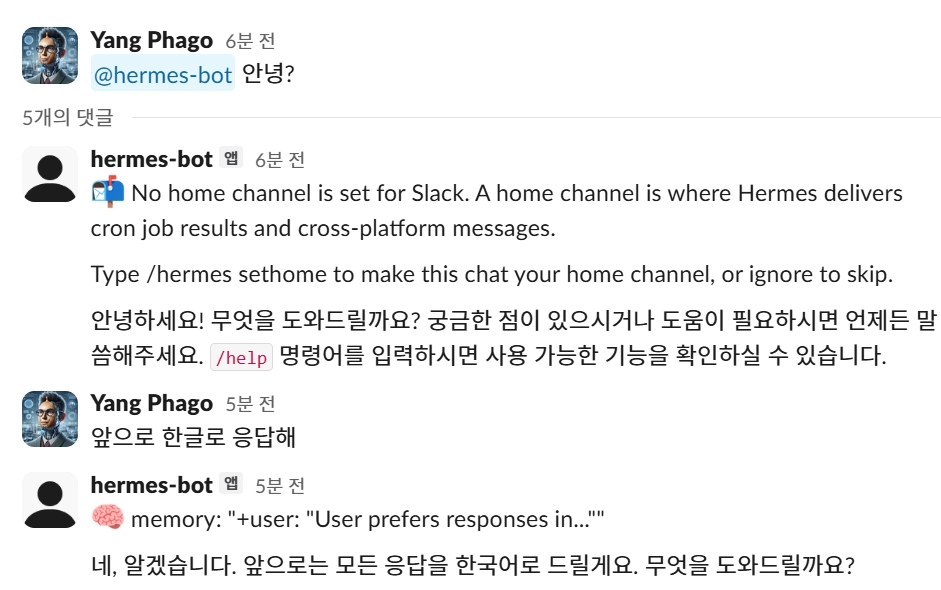
5. Ollama + Gemma 4 E2B 연동
5-1.Hermes config.yaml에 Ollama 연동 추가
•
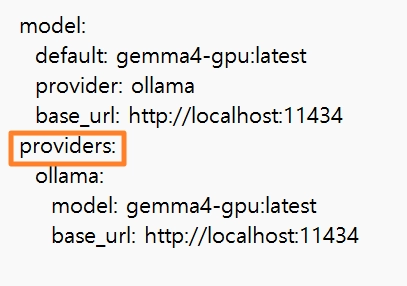
해당 파일을 메모장으로 연뒤, roviders: {} 부분을 찾아서 아래로 교체
providers:
ollama:
model: gemma4-gpu:latest
base_url: http://localhost:11434/v1
Bash
복사
•
저장 후 gateway 재시작
hermes gateway restart
Bash
복사
5-2.Ollama 연동 확인하기
•
슬랙에서 사용중인 모델 확인하기
@hermes-bot 안녕, 지금 어떤 모델 쓰고 있어?
Bash
복사

•
기본 모델을 Ollama로 변경하기
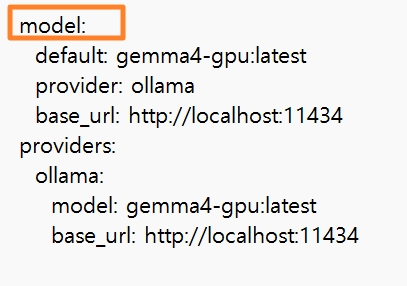
•
올라마 모델을 hermes에 인식시키기
hermes model
Bash
복사
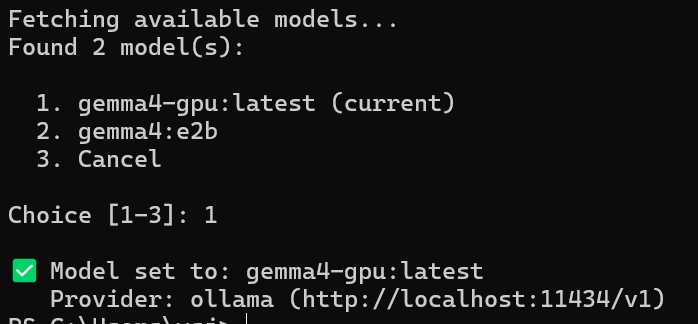
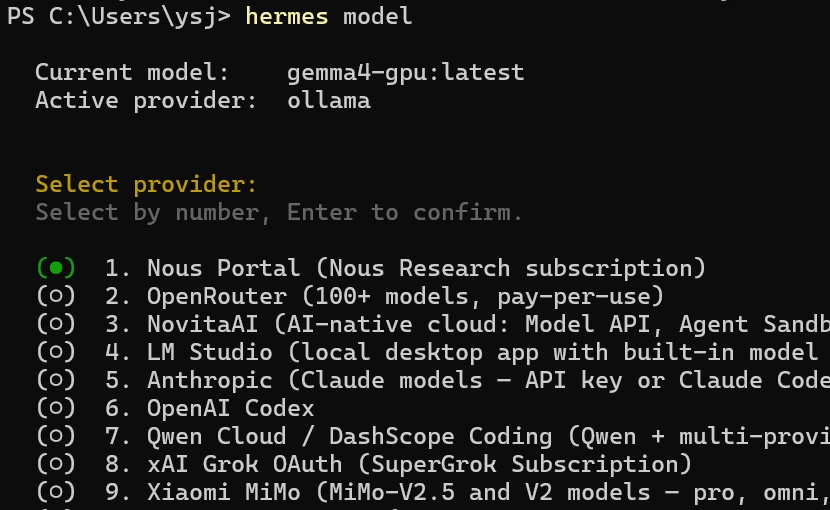
•
설정이 바뀔때 마다 다음 명령어로 hermes 재실행
hermes gateway restart
Bash
복사
5-3.대화기록 확인
•
파워셀에서 다음 명령어 입력
hermes logs
Bash
복사
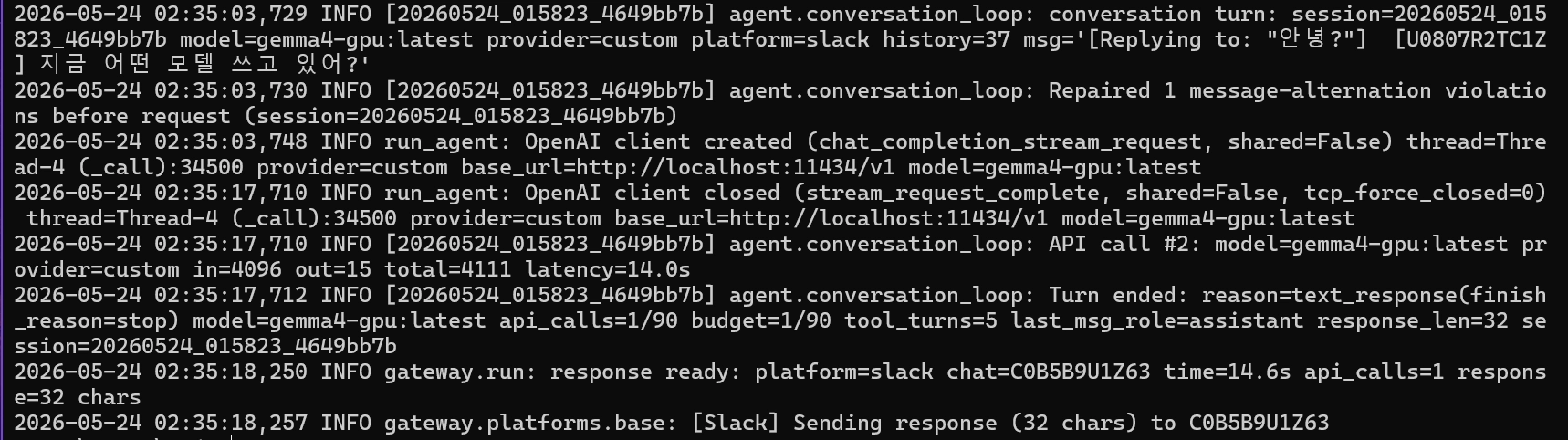
6. Gemini API 키 준비
Google AI Studio에서 API 키를 확인가능
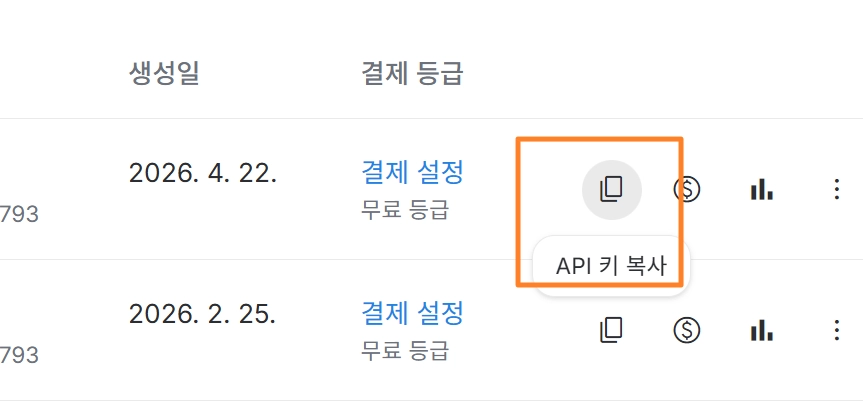
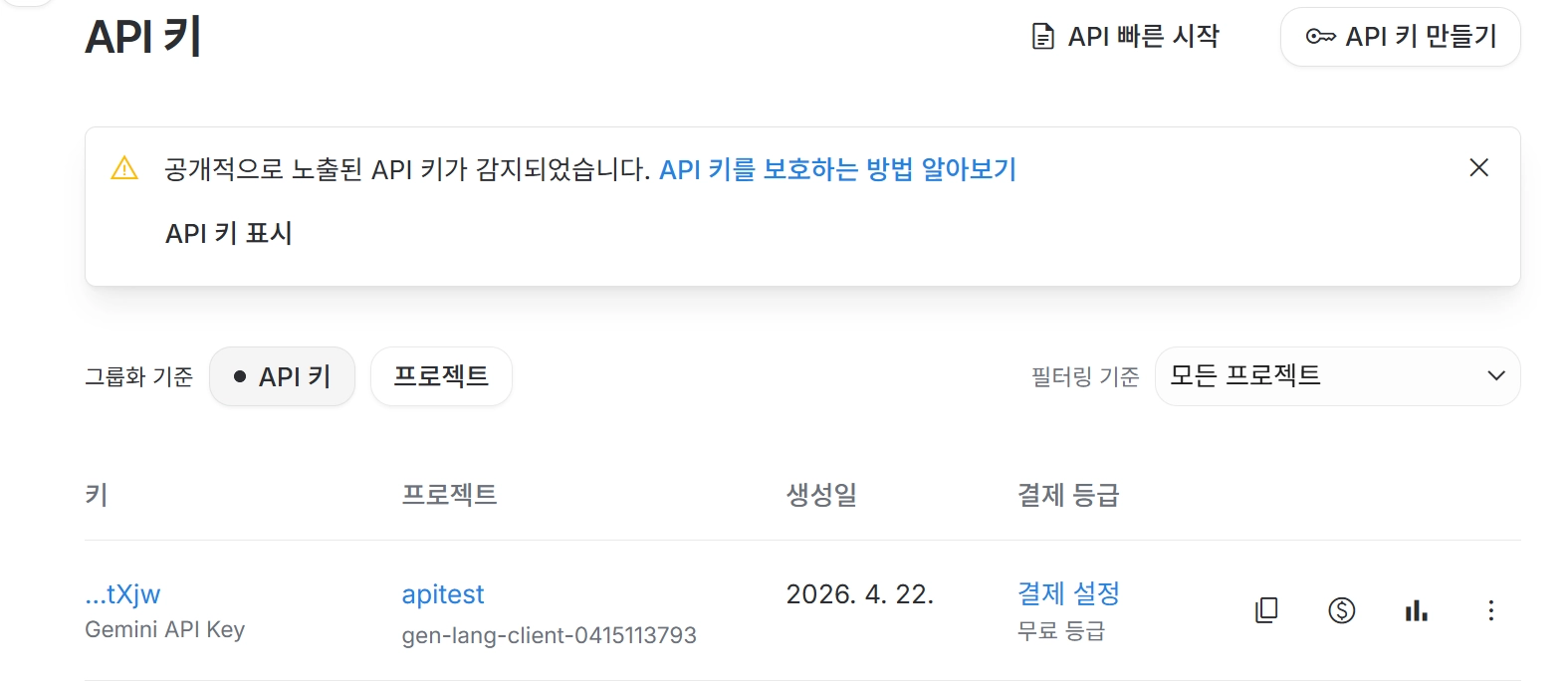
API 키 확인
https://aistudio.google.com 접속
→ Get API Key → API 키 복사
Plain Text
복사
7. Hermes Agent fallback 설정
•
fallback은 PC on/off에 따른 모델 자동 변환
PC 켜져있을 때 (평상시)
├── 단순 → Gemma 4 E2B 로컬 (비용 0원)
├── 중간 → Gemini 3.1 Flash-Lite (무료 티어 소진 후 유료)
└── 복잡 → Gemini 3.5 Flash (무료 티어 소진 후 유료)
PC 꺼졌을 때 (재부팅 / 점검)
├── 로컬 모델 없음 → 자동 감지
├── 단순 → Gemini 3.1 Flash-Lite로 자동 대체
└── 복잡 → Gemini 3.5 Flash
Plain Text
복사
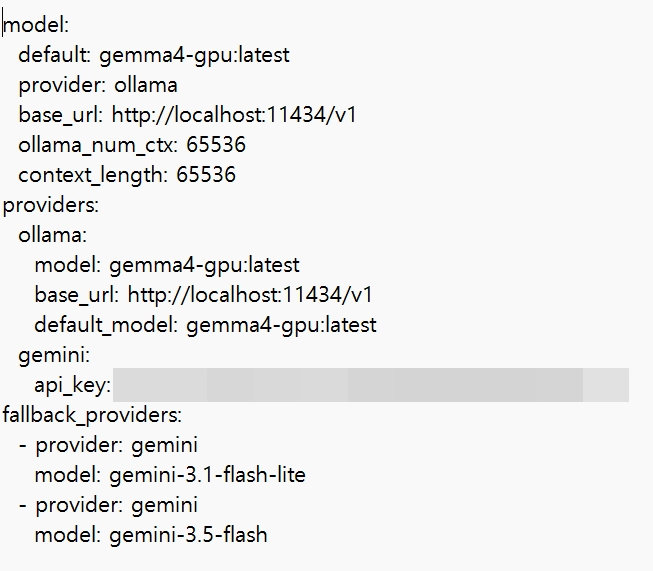
7-1.config.yaml에서 총 2군데 수정하기
7-2. gemini api_key 수정
gemini:
api_key: "YOUR_GEMINI_API_KEY"
Bash
복사

7-3.fallback_providers 설정(PC on/off상태일때의 모델 우선순위)
providers:
ollama:
model: gemma4-gpu:latest
base_url: http://localhost:11434/v1
gemini:
api_key: "YOUR_GEMINI_API_KEY"
fallback_providers:
- provider: gemini
model: gemini-3.1-flash-lite
- provider: gemini
model: gemini-3.5-flash
YAML
복사
7-3. 동작 방식
Hermes fallback_providers 설정 한 번으로 자동 전환됨. 별도 코드 불필요
7-4. 전환 테스트(PC on/off에 따른 모델 자동 변환 테스트)
•
로컬 모델을 자동으로 종료한뒤, 모델변환이 일어나는지 확인하기
•
Ollama를 강제로 중지시키고 질문하면 자동으로 Gemini로 전환되는지 확인할 수 있음
# Ollama 중지
taskkill /F /IM ollama.exe
Bash
복사

•
중지 후 슬랙에서
대한민국의 교육제도 장단점을 분석해줘
Bash
복사
•
응답이 오고난뒤, 파워셀에서 확인 model=gemini-3.1-flash-lite 로 찍혀있으면 2단계 정상 작동
model=gemini-3.1-flash-lite 로 찍혀있으면 2단계 정상 작동
hermes logs
Bash
복사
8. Hermes Agent 3단계 모델 라우팅 + fallback 설정
작업 난이도에 따라 로컬 모델 ‘3.1Flash-Lit’e 또는 ‘3.5 Flash’로 수동 전환되도록 설정
PC 켜져있을 때 (평상시)
├── 단순 → Gemma 4 E2B 로컬 (비용 0원)
├── 중간 → Gemini 3.1 Flash-Lite (무료 티어 소진 후 유료)
└── 복잡 → Gemini 3.5 Flash (무료 티어 소진 후 유료)
PC 꺼졌을 때 (재부팅 / 점검)
├── 로컬 모델 없음 → 자동 감지
├── 단순 → Gemini 3.1 Flash-Lite로 자동 대체
└── 복잡 → Gemini 3.5 Flash
Plain Text
복사
8-1. 핵심 원리
•
Hermes는 smart_model_routing 모드를 지원해서 짧고 단순한 턴은 저렴한 모델로, 복잡한 턴은 고성능 모델로 자동 라우팅할 수 있었으나, v0.13.0에서 제거되어, 수동번환이 더 효율적이게 되버림
단순 → model=gemma4-gpu:latest
복잡 → model=gemini-3.1-flash-lite 또는 gemini-3.5-flash
8-2. 모델 별칭을 통한 모델 자동 변환
•
config.yaml 맨 아래에 추가하기
# 파일 맨 아래
model_aliases:
local:
model: gemma4-gpu:latest
provider: ollama
fast:
model: gemini-3.1-flash-lite
provider: gemini
powerful:
model: gemini-3.5-flash
provider: gemini
YAML
복사
•
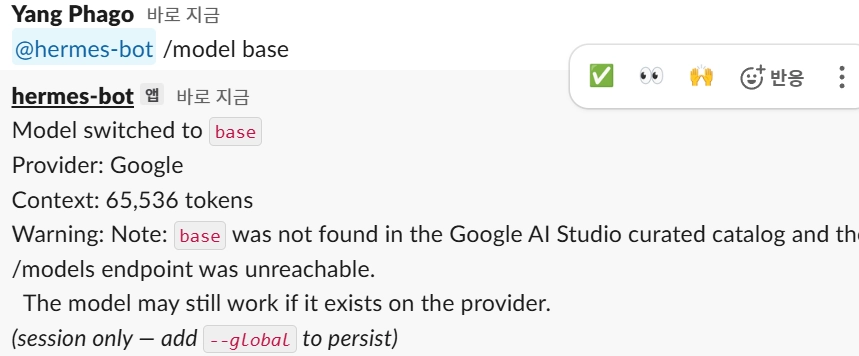
이 후 슬랙에서 모델 전환 → 이후 답변확인하기
@hermes-bot /model fast
@hermes-bot /model powerful
YAML
복사


•
이렇게 스위치가 된 다음에 질문을 넣어야 함!

•
주의1: 모델 스위치와 질문을 같이하면 절대X

•
주의2: 잘못된 별칭을 부르면 안됨
9. 기타
9-1. 하드웨어 최소 사양
항목 | 최소 | 권장 |
CPU | 4코어 이상 | 8코어 이상 |
RAM | 16GB | 32GB |
GPU VRAM | 없어도 됨 (API만 사용 시) | 8GB (로컬 E2B 실행 시) |
저장공간 | 50GB 여유 | 100GB 이상 |
네트워크 | 유선랜 권장 | 유선랜 |
OS | Windows 10 이상 | Windows 11 |
GPU 없어도 Gemini API만으로 Hermes 운용 가능. 로컬 LLM은 선택사항임